

Почему уточняющие операторы убивают вашу лидогенерацию?
Если вы – владелец бизнеса или практикующий специалист по контекстной рекламе, то заголовок статьи, вероятно, уже нарушил ваше душевное спокойствие. Если так – то вы, вероятно, многое упускаете. Впрочем, у ваших конкурентов, скорее всего, ошибок не меньше – успех тут зависит больше от того, кто быстрее среагирует.
В Директе, да и в контекстной рекламе в целом, существует множество мифов и заблуждений: от самого популярного «Директ не окупается», до помешательства на продвинутой аналитике при месячном бюджете кампании в 30000 рублей. Сегодня мы попробуем разобраться с одним из этих мифов, под названием «Как сделать контекстную кампанию своими руками» (бесплатно, без регистрации и СМС).
Разрушение мифов: «Как сделать контекстную кампанию своими руками?»
Итак, трудно сказать почему так произошло, но подавляющие большинство предпринимателей и профильных специалистов работают по следующей схеме:
1) Спарсим семантическое ядро из Wordstat и немного почистим его при помощи самых примитивных инструментов
2) Создадим кампанию, в которой 1 слово = 1 объявление
3) Применим ко всем фразам оператор «кавычки» в формате «ключевое слово» или «!ключевое !слово»
4) Запустим кампанию
5) В этом пункте обычно принято писать что-нибудь про лиды, звонки или просто писать «Профит!». Однако на практике, такая кампания дает в 4-5 раз меньше клиентов, чем могла бы, и это еще в том случае, если бизнес оказывается в состоянии окупить получаемый трафик.
Если в схеме, которая приведена выше, вы нашли знакомые вам черты – читайте дальше.
Проблема концепции: почему уточняющие операторы забирают у вас клиентов?
Наиболее проблемный пункт приведенной выше распространенной схемы – это пункт 3: «Применим ко всем фразам оператор «кавычки»»
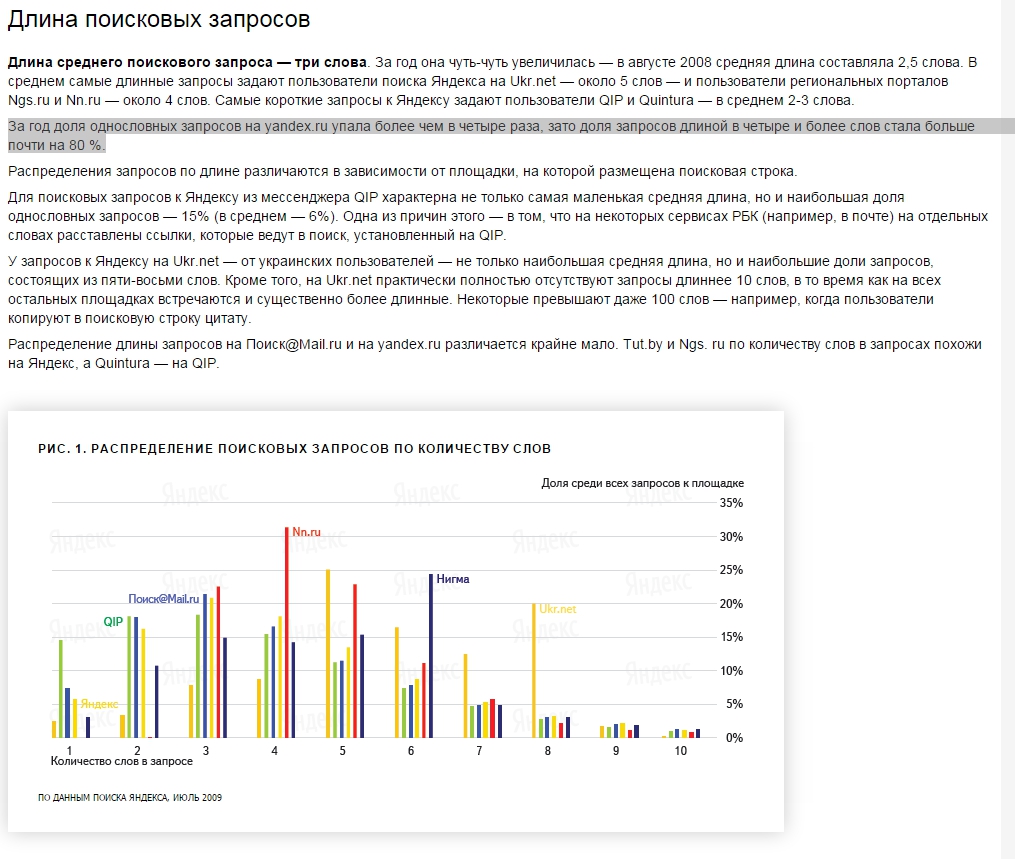
Давайте обратимся к цифрам. Как известно, год от года средняя длина запроса только растет, об этом можно узнать из публично доступных исследований Яндекса:
Исследование 2008 года, доля 4-словников 26%, средняя длина 2,5 слова против 1,2 слова в 1997 году на момент запуска Яндекса:

Исследование 2009 года, средняя длина 3 слова против 2,5 слова в 2008 году. Цитата:
«За год доля однословных запросов на yandex.ru упала более чем в четыре раза, зато доля запросов длиной в четыре и более слов стала больше почти на 80%».

Исследование 2011 года, средняя длина 3,2-3,5 слова против 3 слов в 2009 году. Цитата:
«Мужские запросы к Яндексу немного короче женских — в среднем 3,2 и 3,5 слова соответственно».
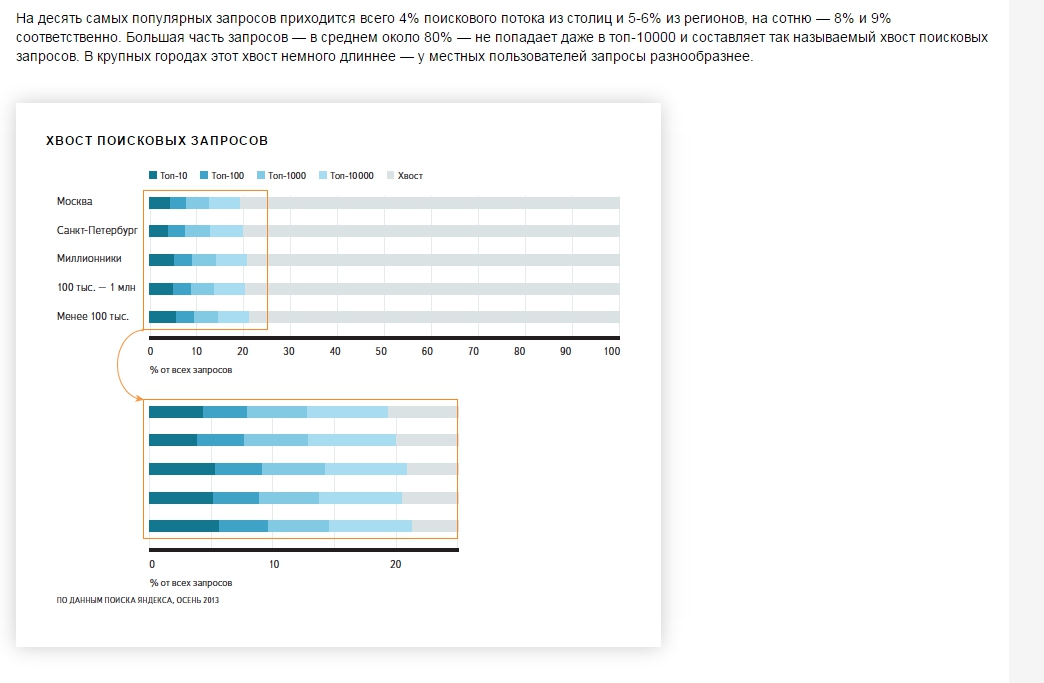
Исследование 2014 года уже не дает цифр по длине запросов, однако сообщает, что:
«Большая часть запросов — в среднем около 80% — не попадает даже в топ-10000 (прим. авт. – по трафику) и составляет так называемый хвост поисковых запросов. В крупных городах этот хвост немного длиннее — у местных пользователей запросы разнообразнее».

А теперь, внимание - именно в этом месте и происходит весь фокус. Фокус – в намеренном умолчании. Яндекс честно говорит нам, что основа поиска – это низкочастотный хвост. Однако этот низкочастотный хвост невозможно найти в Wordstat, его там попросту нет.
Пример:
Wordstat - парсинг по запросу «мебель» (май 2015 )без указания региона, с глубиной 6, получено 112175 уникальных запросов, из которых у 98980 запросов точная частотность отличается от 0.
База MOAB - парсинг без указания региона, дает 3 987 908 запросов, то есть – почти 4 миллиона ключевых слов с подтверждённым траффиком, отличным от нуля.
Разница – в 40 раз.
А теперь сухие цифры: мы получили ключи из базы MOAB путем парсинга открытых счетчиков Яндекс.Метрики, спарсив при этом полную историю по 100 000 сайтов из ~30 000 000 сайтов, подключенных к Метрике. То есть, спарсив данные только по 3% сайтов, мы получили в 40 раз больше ключевых слов, чем есть в Wordstat. Возникает вопрос: какой процент от известных Яндексу только из Метрик ключевых слов Яндекс отдает в Wordstat?
На примере данной выборки, можно подсчитать, что всего лишь около 0, 075%.
Конечно, данная оценка очень груба, однако она помогает понять сколь недостоверны публичные источники ключевых слов – пользуясь только Wordstat, вы:
а) получаете статистически недостоверную выборку. Люди задают гораздо больше расширенных запросов, чем можно увидеть в Wordstat. 7 и 8-словники могут генерировать множество лидов и десятки переходов в день, при этом их точная частотность Wordstat будет равной или близкой к нулю за счет задержки в получении данных и/или некорректном их отображении
б) получаете наиболее переоцененные и конкурентные запросы, доступные всем другим рекламодателям
и, наконец, самое важное:
в) в Wordstat вы получаете те самые 20% наиболее частотных запросов, которые формируют «топ» тематики. Затем обычно фильтруется мусор и запросы заключаются в «кавычки», ограничивая область показов, чтобы добиться большего CTR.
Но проблема в том, что собранные вами в Wordstat запросы несут только 10-15% от общего трафика тематики. То есть, используя операторы, вы своими руками отказываетесь от 85% тематического трафика тематики, ограничивая ваш охват. Эти 85% - это ультранизкочастотные запросы. Их очень много, они состоят из большого количества слов и постоянно перекомбинируются. На момент составления вашей кампании, многие из них могут быть вообще еще не заданы к поиску – но суммарно все это огромное разнообразие редких запросов сформирует те самые дешевые лиды в пустых микронишах, о которых все так любят говорить.
Таким образом, мы разъяснили проблему. Большая часть трафика в поисковиках формируется запросами, которых нет в Wordstat, зачастую их нет вообще нигде, поскольку они зачастую еще вообще не заданы, либо же были заданы 1-2 раза. Таких запросов очень много, суммарно они формируют гигантский траффик. Использование уточняющих операторов, в особенности при работе с наиболее расхожими запросами из Wordstat, позволяет вам бороться лишь за 10-15% от реально возможных показов.
Таким образом, мы должны ответить на несколько вопросов:
- как рекламироваться по большому объему НЧ-запросов?
- как рекламироваться по запросам, которые еще не заданы?
- как получать максимум охвата по нужным запросам, надежно отсекая лишнее? Как отсечь все «некоммерческие» запросы, когда мы даже не знаем их точной формулировки?
Именно об этом мы сейчас и поговорим.
Тонкая красная линия: минус слова или уточняющие операторы?
Когда вы работаете с Директом, ваша задача, с формальной точки зрения, очень проста – по крайней мере, для поискового размещения. У Яндекса ежедневно есть некая сумма показов, которую он может продать для поискового размещения вообще в целом за сутки. Ваше объявление занимает некоторую часть от этой суммы, то есть вы забираете на ваше объявление у Яндекса часть показов. В идеале, вы должны показывать объявление только тем, кто способен кликнуть по нему, так, чтобы количество кликов было как можно ближе к количеству показов. Если из 100 показов, которые вы забрали, по вашему объявлению кликнут 1 раз, Яндекс возьмет с вас 10 долларов за 1 клик, то есть при CTR 1% цена за клик для вас составит 10 долларов. Если из 100 показов, которые вы забрали, по вашему объявлению кликнут 10 раз, Яндекс возьмет с вас 1 доллар за 1 клик, то есть при росте CTR в 10 раз до 10% цена за клик для вас снизится в 10 раз.
Важно здесь то, что Яндекс в любом случае получит те же самые 10 долларов, которые он изначально хотел получить, отдавая вам 100 показов – то есть, на самом деле Яндекс продает показы, упаковав это в форму «платы за клик».
Это, конечно же, очень грубая схема, однако ее достаточно, чтобы понять смысл игры: когда вы показываете ваше объявление тем, кому оно не нужно (= тем, кто по нему не кликает), Яндекс страхуется от потери прибыли, а вы – теряете деньги, переплачивая за дорогие клики. Таким образом, уточним задачу – нам нужно минимум показов и максимум кликов, при этом мы не знаем и не можем знать большей части запросов, с которыми работаем, у нас наблюдается явный дефицит информации.
Как же быть в такой ситуации?
В активе: у нас есть инструменты для управления количеством показов (операторы, минус-слова), у нас есть инструменты для расширения семантического ядра (поисковые подсказки через Key Collector или MOAB Suggest, собственная статистика сайта, статистика чужих сайтов через MOAB Pro)
В пассиве: мы не знаем точной формулировки большинства запросов
Теперь мы подошли к самому интересному – пошаговой схеме действий. Время теорий прошло, настало время практики.
Шаг 1
На первом этапе нам нужно семантическое ядро, отличающееся максимальной статистической достоверностью.
Что такое статистическая достоверность?
Когда вы работаете с большими данными, вы зачастую не можете (да это и не нужно), обработать все доступные данные. В этом случае вы берете некий статистически достоверный срез данных, анализируете его, а затем используете полученные данные, также, как если бы проанализировали весь массив. Говоря простым языком, можно привести пример социологических центров – «Левада центра» или «ВЦИОМ»: при проведении соцопросов обычно опрашивается только 1600 человек, распределенных равномерно по всей России, при этом оказывается, что распределение мнений в среди всех людей вообще почти не отличается от распределения мнений внутри опрошенной выборки в 1600 человек.
Также поступим и мы – на первом этапе постараемся получить самую достоверную выборку, до которой сможем дотянуться. Об источниках такой выборки мы подробно писали здесь. Отмечу, что и по сей день наиболее полным и достоверным источником семантики является статистика сайта с богатым органическим или контекстным трафиком.
Итак, мы получили выборку. Возьмем, для примера, выборку по запросу «натяжные потолки» из базы MOAB Pro.
Выборка из MOAB Pro – 391 045 запросов, для ознакомления можно скачать файл с 2000 наиболее частотных запросов
Выборка из MOAB Suggest – 102 166 запросов, вы можете скачать полный файл
Шаг 2
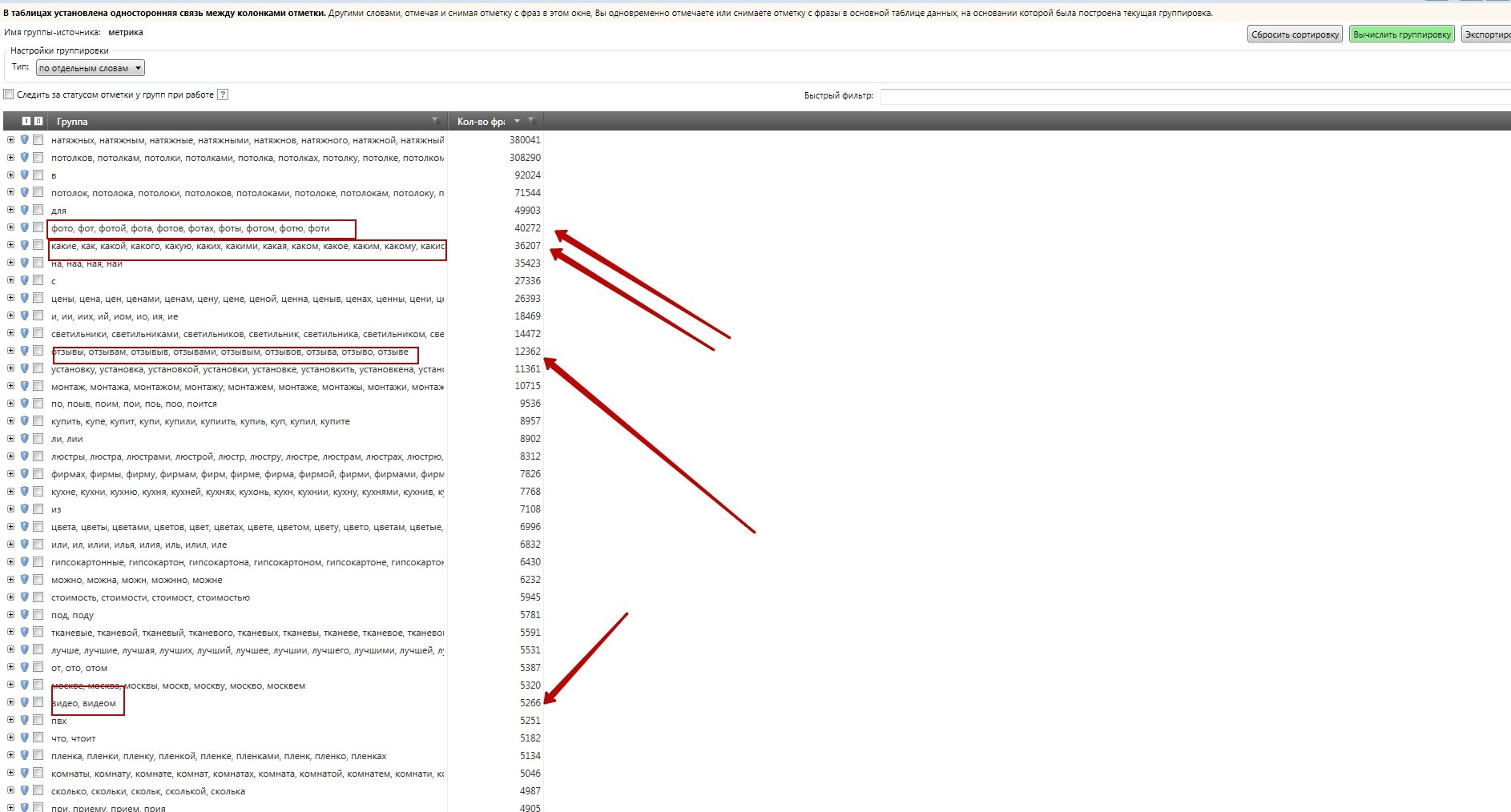
Только на первый взгляд выборка кажется нагромождением хаотичных запросов, не связанных между собой. На самом деле, простейшая кластеризация, выполняемая при помощи инструмента «Анализ групп» в Key Collector выявляет разбиение ядра на совершенно четкие сегменты.
Обратите внимание, что кластеризацию нужно выполнять «по отдельным словам», это указывается на панели настроек анализатора.
Подобный анализ, например, как это видно, на указанном скриншоте, выявляет совершенно четкую группу информационных запросов «расплавился» - все запросы содержат различные группы этого глагола. Это показывает нам, что существует сегмент реальных интересов пользователей, группируемых вокруг проблемы расплавления натяжного потолка.
Несмотря на то, что мы, в сущности, знаем лишь малую часть реальных запросов этого сегмента, мы можем добавить сам глагол «расплавиться» в стоп-файл, что полностью запретит показы по любым вариациям этого запроса, то есть «отрежет» трафик по всему сегменту.
Подобную операцию минусации сегмента можно провести и для более популярных сегментов, например:

Очевидно, что такие сегменты, как «отзывы» или «видео» вряд ли дадут высокую конверсию в покупателей, очевидно, что их лучше добавить в стоп-слова. Обратите внимание на цифры рядом с сегментами – эти цифры, фактически, означают количество запросов внутри сегмента - например, сегмент «фото» содержит почти 40000 запросов, грубо говоря, это около 10% трафика во всей тематике.
А теперь представьте – анализируя сегментацию, мы потратили всего 1-2 минуты, чтобы просмотреть первую страницу результатов. За это время мы добавили в стоп-файл четыре сегмента:
- отзывы
- какие
- фото
- видео
Эти 4 сегмента суммарно содержат около 94 000 запросов, что составляет, при грубой оценке, четверть трафика в тематике. То есть, вопрос даже не в количестве, а в качестве минус слов – можно придумать или позаимствовать у друга сколько угодно минус слов, но вот какое отношение они будут иметь к реальному семантическому ядру?
Попробуем развить эту идею дальше: ведь если просмотреть верхние 20% строк в кластеризации и отметить как стоп-слова «ненужные» бизнесу сегменты, мы «отрежем» по количеству 90-95% «ненужного» трафика.
Если вернуться немного назад, мы увидим, для чего нам нужен статистически достоверный массив – сегменты статистически достоверного массива с очень высокой точностью копируют реальный массив с множеством неизвестных нам запросов.
При этом, несмотря на то, что запросы могут быть сформулированы как угодно, сами сегменты все равно останутся такими же – и при выполнении кластеризации и ее последующем анализе, мы все равно «выловим» и «отрежем» большую часть неэффективных для бизнеса сегментов.
Таким образом, можно сформулировать несколько общих правил:
- для минусации нам нужен максимально статистически достоверный файл, максимум запросов с подтвержденным трафиком – искусственная семантика здесь неэффективна
- минусация должна выполняться на основе кластеризации, при этом, если вам нужен действительно точный и эффективный контекст, вы должны просмотреть хотя бы верхние 20% строк в кластеризаторе и выявить неэффективные сегменты, составив из них стоп-файл. Этот стоп файл будет достаточно большим, однако именно он даст вам возможность на следующем этапе отказаться от использования уточняющих операторов – ведь даже если вы не знаете всех запросов, вы можете быть уверены, что ваш стоп-файл станет надежным щитом, который защитит вас от «ненужных» показов.
Иными словами, у нас есть два инструмент регулирования охвата – стоп-файл и уточняющие операторы. Обладая статдостоверным массивом, мы по максимуму используем минус-слова, перенося именно на них акцент в «очистке» траффика от мусора.
При этом уточняющие операторы мы используем по минимуму, что, в свою очередь, дает нам максимальный охват как раз по неизвестным нам запросам, которые, по сути, являются расширениями от тех запросов, которые мы собрали.
В данном случае уместно напомнить, что Директ понимает формы слов «расплавиться» и «расплавился» - то есть, не важно какую именно форму слова вы добавите в стоп-файл, однако «расплавленный» уже нужно добавлять отдельно – части речи воедино Директ не связывает. Все спецсимволы, кроме точки, для Директа равнозначны пробелу – то есть, числовое минус-слово (например, артикул) «49-53» будет распознано как два отдельных минус слова, разделенных пробелом, в то время, как «49.53» будет распознано как единое стоп-слово.
Также важно упомянуть чисто технический момент: наиболее удобным способом очистить сам по себе массив ключевых фраз от мусора, чтобы перейти к следующему этапу группировки, являются регулярные выражения, реализованные в Key Collector, о которых многие незаслуженно забывают или попросту не знают.
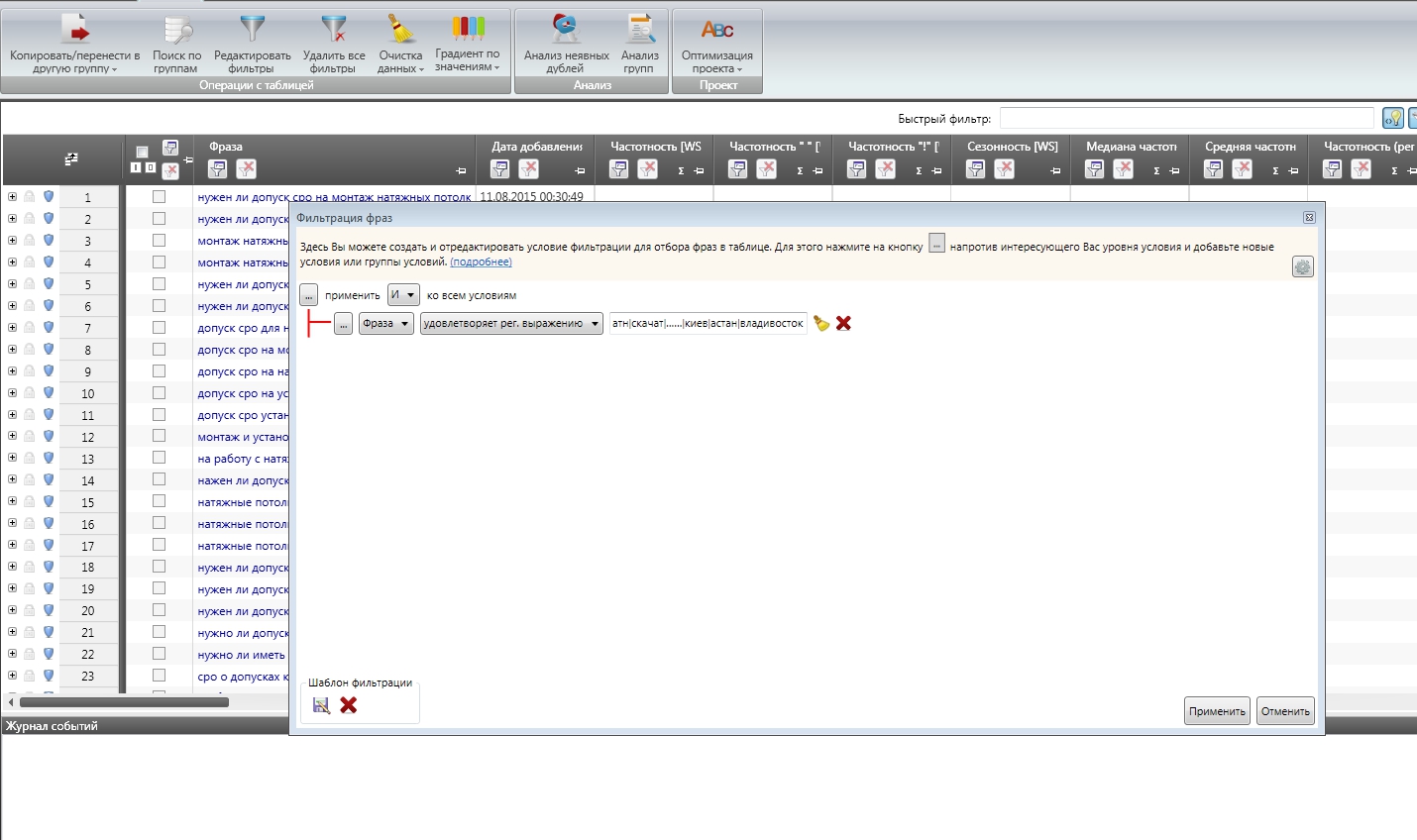
Итак, представим, что у вас есть стоп-файл в формате Директа, который вы собрали, анализируя кластеры в частотном словаре:
- отзывы, - видео, -бесплатно, -скачать,….-киев, -астана, владивосток
Вы можете превратить эти фразы в конструкцию вида:
отзыв|видео|бесплатн|скачат|……|киев|астан|владивосток
А затем добавить полученную конструкцию в Key Collector на вкладке с неочищенным массивом.
В результате в полученной выборке будут все фразы, которые подходят под одно из условий, то есть содержат или «отзыв» или «видео» или «бесплатн», и так далее. Аккуратнее нужно быть с неоднозначными словами типа «ноги» - условие формата «ног» заберет под фильтр и «ногинск», и «ноггано», и «треноги», при этом «ногинск» и «ноггано» могут являться стоп-словами в конкретном контексте, а «треноги» - нет.
Преимущество в том, что можно, с одной стороны, быстро убрать из массива все ненужные фразы, с другой стороны – вы можете применять полученное регулярное выражение в дальнейшем к массивам схожей тематики, экономя время на очистку от ненужных запросов.
Как добиться высокого CTR по неизвестным запросам?
Теперь представим, что мы отобрали огромный стоп-файл, благо теперь допустимый размер стоп-файла в Яндекс.Директе – 20 000 знаков. Таким образом, мы «отрезали» весь траффик с потенциально низкой конверсией – все сегменты, маркерами которых являются некие характерные слова, добавлены в наш стоп-файл.
Однако, мы сделали только половину дела. Перед нами все еще стоит вопрос – как добиться эффективных показов не только и не столько по тем запросам, которые вошли в наше семантическое ядро, но и по их перекомбинациям и расширениям.
Наиболее эффективный путь – дальнейшая работа с сегментацией. Попытайтесь отвлечься от неэффективного подхода «1 ключ = 1 объявление». Представьте, что одно объявление – это один сегмент из «Анализа групп» с привязанными к нему запросами. Давайте попробуем представить в чем плюсы и минусы такого подхода.
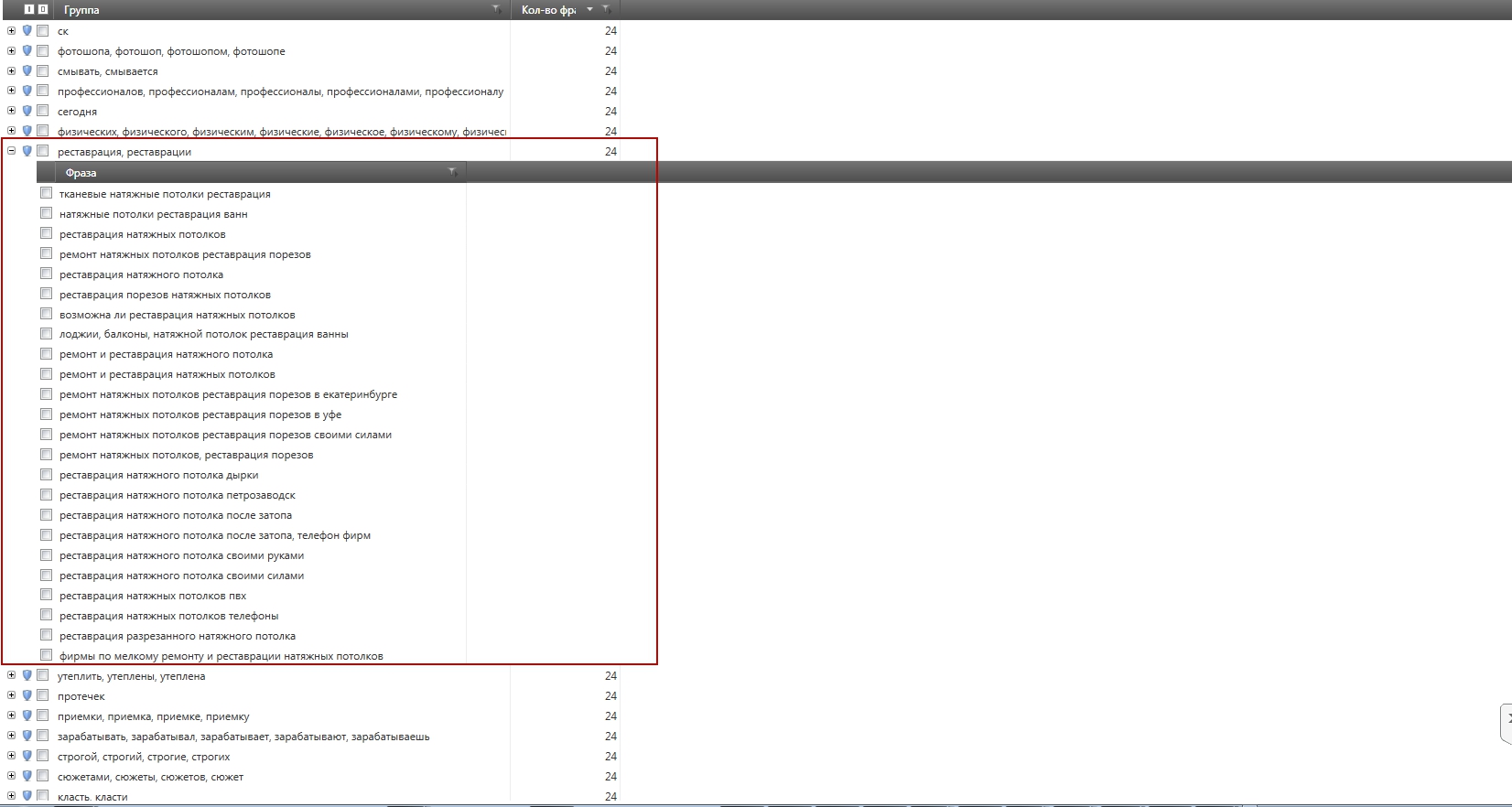
Возьмем для примера сегмент «реставрация». Внимательный читатель, конечно, может отметить, что в сегменте остались запросы, которые формально можно считать «мусорными» - но и серьезную очистку мы не проводили для этого массива – просто показали на небольшом примере, как это делается на практике. Поэтому условно представим, что все запросы внутри сегменты – целевые.
Итак, в сегменте «Реставрация» содержится 24 ключевых запроса:
тканевые натяжные потолки реставрация
натяжные потолки реставрация ванн
реставрация натяжных потолков
ремонт натяжных потолков реставрация порезов
реставрация натяжного потолка
реставрация порезов натяжных потолков
возможна ли реставрация натяжных потолков
лоджии, балконы, натяжной потолок реставрация ванны
ремонт и реставрация натяжного потолка
ремонт и реставрация натяжных потолков
ремонт натяжных потолков реставрация порезов в екатеринбурге
ремонт натяжных потолков реставрация порезов в уфе
ремонт натяжных потолков реставрация порезов своими силами
ремонт натяжных потолков, реставрация порезов
реставрация натяжного потолка дырки
реставрация натяжного потолка петрозаводск
реставрация натяжного потолка после затопа
реставрация натяжного потолка после затопа, телефон фирм
реставрация натяжного потолка своими руками
реставрация натяжного потолка своими силами
реставрация натяжных потолков пвх
реставрация натяжных потолков телефоны
реставрация разрезанного натяжного потолка
фирмы по мелкому ремонту и реставрации натяжных потолков
Ценность сегментов состоит не в конкретных фразах, а в том, что они дают нам знание о том – есть вот такая группа интересов пользователей. Значит, мы можем создать релевантное группе объявление:
Заголовок: Реставрация натяжных потолков
Текст: Ремонт потолков под ключ! Выезд и оценка бесплатно.
Затем выгружаем объявление в Директ, вместе с приведенными выше ключами и запускаем показы. Ключи, естественно, выгружаем без операторов.
Что же мы получим в результате?
Во-первых, обратите внимание на т.н. «базис» сегмента. Все ключевые слова сегмента включают в себя 3 слова – реставрация, натяжных, потолков. Это означает, что объявление будет генерировать показы только по тем запросам, которые содержат все 3 слова одновременно + какие-либо дополнения и расширения, о которых мы не знаем.
То есть, вполне вероятно, что многие ключи сегмента не будут генерировать показов в принципе. Большая часть показов придется на запрос «реставрация натяжных потолков», так как именно он будет привлекать расширенные показы по ключам формата «реставрация натяжных потолков + расширение».
Одновременно с этим, мы не будем привлекать показы по ненужным нам неизвестным расширениям, за счет наличия качественного стоп-файла. А что же с кликабельностью по столь нужным нам «неизвестным» запросам?
Взглянем на выдачу:

Рекламируясь по любому из ключевых слов сегмента, в том числе и по неизвестному расширению, вы получите просто потрясающий CTR: наиболее важного для пользователя слова «реставрация» нет ни в одном из объявлений Директа, а ведь именно оно в заголовке объявления и привлечет его наибольшее внимание, причем на любой позиции спецразмещения.
Более того, вы заберете трафик у органической выдачи:

Ни одного слова «реставрация» нет в заголовках органической выдачи и Директа в самом конкурентном регионе страны – в Москве, а в Директе в заголовках нету даже синонимичного «ремонта»! Было бы непозволительным подарком конкурентам не воспользоваться такой ситуацией – тем не менее, это стандартная ситуация для большинства низкочастотных выдач.
Несомненно, что в таких условиях, вы сможете получать максимум трафика даже не с первой, а с любой, самой дешевой позиции спецразмещения. Позже мы обсудим, как именно использовать и обратить себе во благо эту ситуацию.
Во-вторых, обратите внимание на то, как составлен заголовок и текст. Заголовок копирует базис группы – три слова, входящие во все ключи сегмента, занимает 29 символов. Затем идет первое предложение текста, состоящее из 24 символов. 24 + 29=53, то есть укладываемся в правило «56 символов». На выдаче на практике получаем объявление:
Заголовок: Реставрация натяжных потолков - Ремонт потолков под ключ!
Текст: Выезд и оценка бесплатно.
В итоге, при запросе любого, пусть даже перекомбинированного запроса в рамках данного сегмента, мы получим как минимум 4 подсвеченных слова в данном заголовке:
- реставрация - 1 вхождение
- натяжных - 1 вхождение
- потолков - 2 вхождения
Обратите внимание, что в расширенный заголовок не случайно попал также и «ремонт» - он слишком часто – аж 8 раз попадается в ключевых словах сегмента, на выдаче по этому запросу «ремонт» подсвечивается в сниппеттах и распознается как синоним. Это важный сигнал – значит, высока вероятность его употребления вместе с базисом группы, а значит – надо в таком случае получить употребление в заголовке, чтобы повысить кликабельность и по таким запросам.
Какие-то из запросов в данной группе сгенерируют показы, какие-то нет.
В любом случае, суммарное качество и количество целевого траффика из кампании, собранной в рамках такой архитектуры, превзойдет любые ваши ожидания по сравнению с кампаниями, собранными в стандартной архитектуре «1 ключ=1 объявление». По опыту клиентов MOAB, которых мы консультировали, в среднем стоимость лида после подобной пересборки кампаний падала в 3-4 раза.
Однако есть очень важный момент: работая со случайным массивом запросов, мы должны все время отслеживать базис каждого объявления. В данном случае под базисом понимается ключевой запрос, который состоит только из тех слов, которые входят в каждое (!) ключевое слово объявления.
В данном случае, базис это - [реставрация натяжных потолков]
Так получилось, что данный ключ естественным образом попал в группу «реставрация». Это приведет, в свою очередь к тому, что при неизвестном нам запросе пользователя - [реставрация натяжных потолков москва проспект ленина] - наше объявление будет показано по этому запросу, так как данный ключ является расширением от [реставрация натяжных потолков].
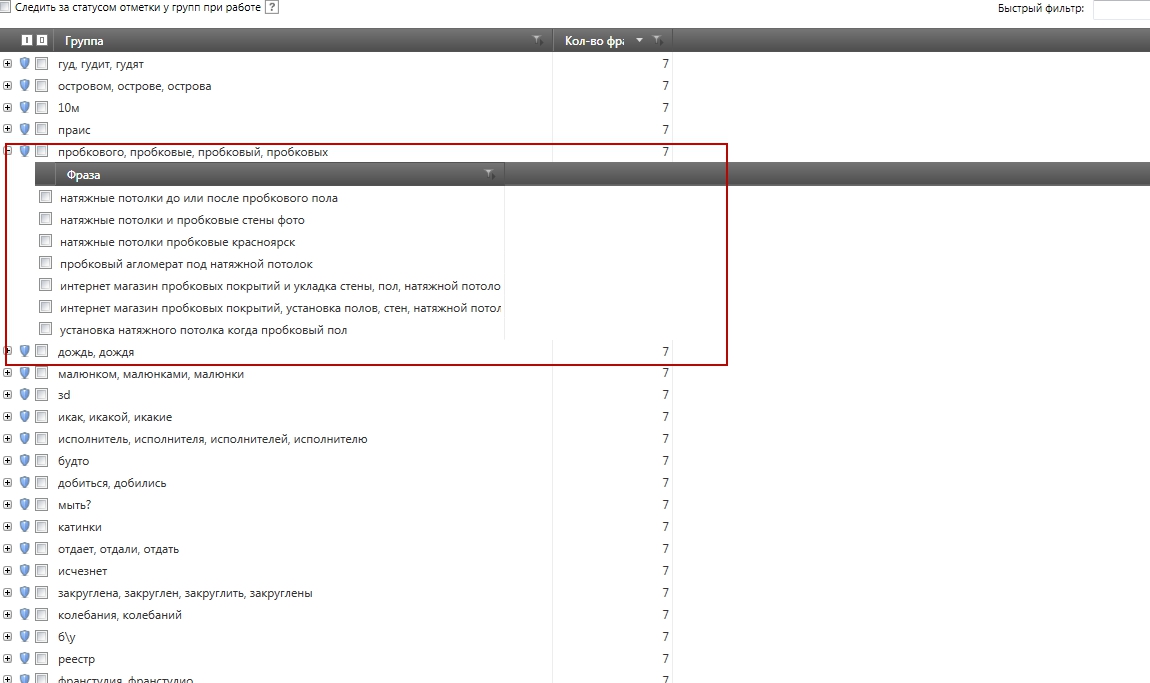
Однако, давайте взглянем на другой сегмент - [Пробковые натяжные потолки]

Дело в том, что когда мы работаем с ядром, то в большинстве случаев, базис сегмента естественным путем оказывается среди ключей сегмента и генерирует показы по расширенным вариантам запроса. Однако, если взглянуть на скриншот, видно, что в данном сегменте базис [Пробковые натяжные потолки] отсутствует, то есть показа по неизвестному запросу - [Пробковые натяжные потолки москва] - не произойдет.
В этом случае, эту ситуацию надо отследить самостоятельно и добавить в группу искусственный, формально говоря, ключ [пробковые натяжные потолки], дабы получить показы по всем неизвестным запросам данного сегмента.
К слову, всем кто хочет действительно серьезно поработать с управлением контекстной рекламой на основе операторов, рекомендую ознакомится с нашей статьей «Шесть секретов контекстной рекламы», в особенности – с пунктом 3, в котором рассказано, какие дополнительные меры можно принять для снижения стоимости показов по сравнительно дорогим запросам из Wordstat, так, чтобы при этом сохранить показы по «неизвестным» запросам.
Как гибко регулировать стоимость клика на основе среднерыночных данных?
Итак, заключительный этап создания кампании – грамотное регулирование ставок. Давайте взглянем на стандартный подход «1 ключ=1 объявление» с точки зрения ставок. Получается, что все рекламодатели работают с Wordstat, забирая оттуда примерно один и тот же набор «коммерческих» фраз. После этого фразы с оператором «кавычки» загружаются в аккаунт и включается кампания. В итоге имеем огромный набор рекламодателей, которые конкурируют за жестко ограниченный набор фраз все вместе. Естественно, это разогревает аукцион конкретно по этим фразам, в то время как конкуренция по «неизвестным» запросам остается сравнительно «спокойной».
Однако оставим теорию – сегодня у нас есть для вас еще несколько важных практических советов.
1. Работайте с рыночной ценой на ваши ключевые слова.
Как ее узнать?
Очень просто: добавьте очищенный массив фраз в Key Collector, а затем снимите стоимость клика по каждой фразе.
В появившемся окне выберите следующие настройки:

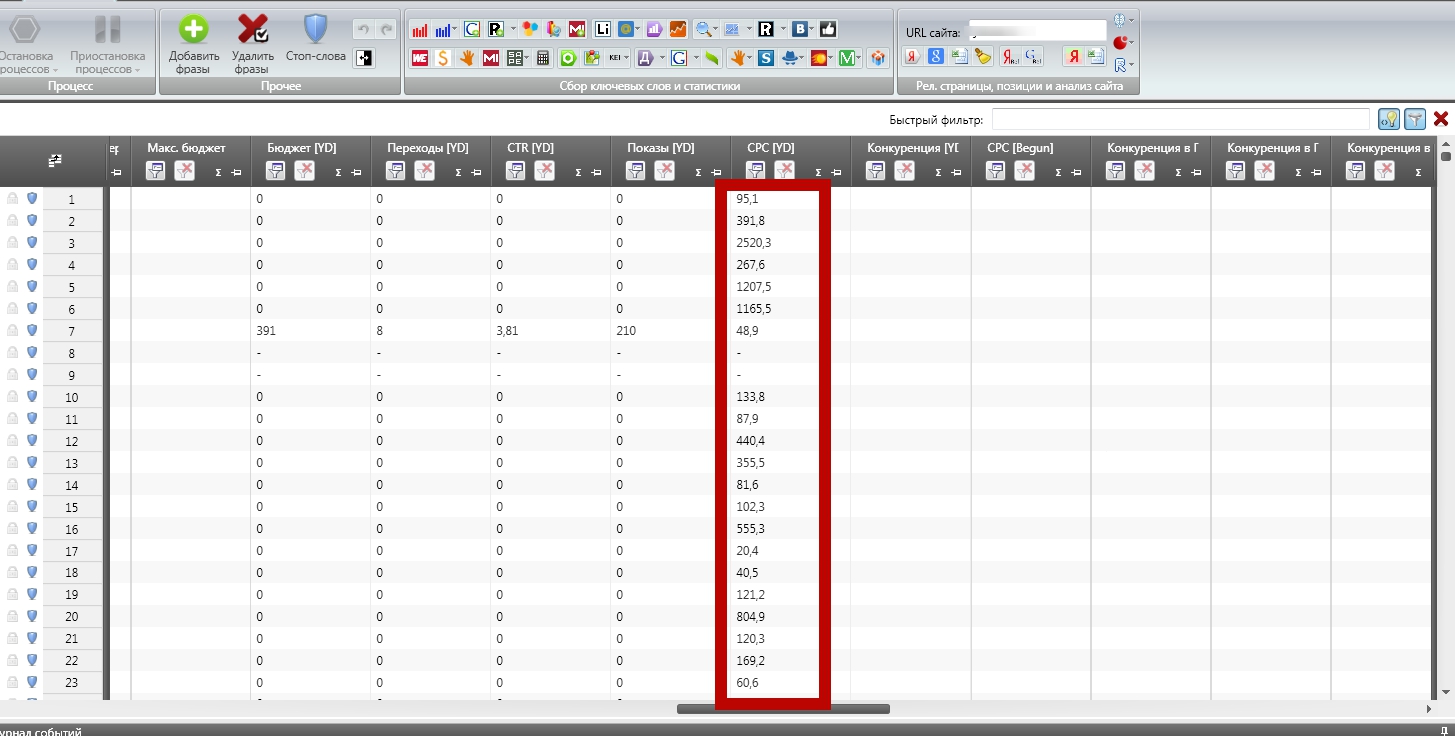
В поле «Задать регион» обязательно задайте регион геотаргетинга, с которым вы работаете. После чего ожидайте некоторое время, а затем обратитесь к информации, полученной в поле CPC YD:

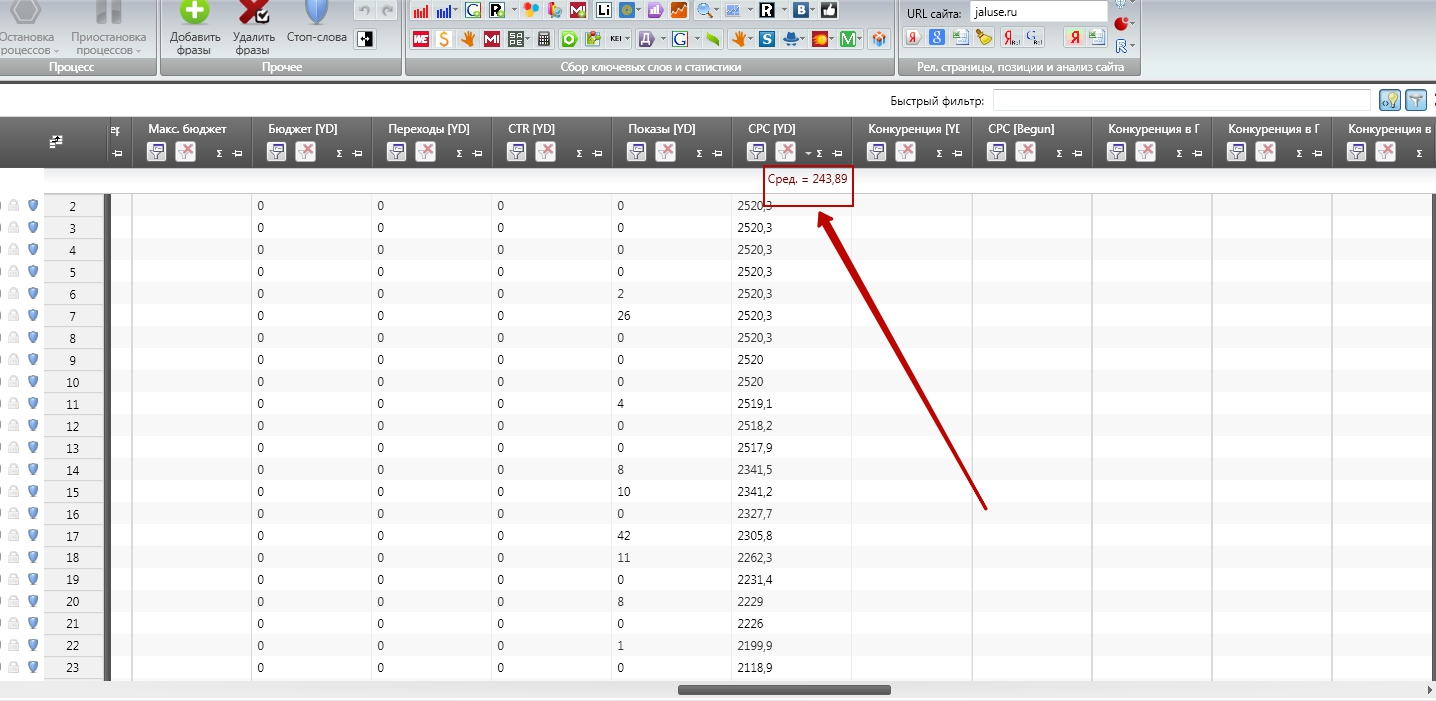
Рассчитаем среднюю стоимость клика по полученному массиву. Затем выбираем «Среднее» и получаем результат:

Полученная цифра почти в 250 рублей – среднерыночная стоимость клика на основе «Прогноза бюджета» Директа. Для расчета прогнозных значений Директ, естественно, берет среднее значение по системе, на практике ваша стоимость клика в среднем будет гораздо ниже.
Однако, получая данное среднее значение и работая с большим массивом фраз, мы можем хотя бы примерно заранее понять, какие фразы являются заведомо переоцененными, а какие – недооценены.
Именно значение средней рыночной стоимости (или его производные, например, средняя стоимость*0,50) мы рекомендуем использовать на первом этапе открутки кампании как максимальную ставку, выставляемую в биддере. Затем эта ставка может быть скорректирована с учетом фактической ситуации по маржинальности и окупаемости контекстной рекламы.
Как работать с биддерами?
Мы работаем с биддером ДиректМенеджер и рекомендуем его нашим партнерам. Среди преимуществ данного биддера – в первую очередь огромный набор переменных, из которых можно писать собственные стратегии и частая обновляемость ставок (до 1 раза в 5 минут).
Для кампаний, созданных по описанной выше архитектуре, мы используем следующую комбинацию стратегий:

Вот текстовый вид основной стратегии:
если (1С меньше 2С и 1С меньше 3С) {
1С + 0.02
} иначе если (2С меньше 1С и 2С меньше 3С) {
2С + 0.02
} иначе {
3С + 0.02
}
Вот текстовый вид дополнительной стратегии:
если (1М меньше 2М и 1М меньше 3М и 1М меньше 4М и 1М меньше 5М и 1М меньше ГП) {
1М + 0.02
}
иначе если (2М меньше 1М и 2М меньше 3М и 2М меньше 4М и 2М меньше 5М и 2М меньше ГП) {
2М + 0.02
}
иначе если (3М меньше 1М и 3М меньше 2М и 3М меньше 4М и 3М меньше 5М и 3М меньше ГП) {
3М + 0.02
}
иначе если (4М меньше 1М и 4М меньше 2М и 4М меньше 3М и 4М меньше 5М и 4М меньше ГП) {
4М + 0.02
}
иначе если (5М меньше 1М и 5М меньше 2М и 5М меньше 3М и 5М меньше 4М и 5М меньше ГП) {
5М + 0.02
}
иначе { ГП + 0.02 }
Что же означают все эти цифры на практике?
Биддер раз в 5 минут обращается к API Директа и получает цены на все позиции спецразмещения по конкретной фразе. Из трех полученных значений для нашей конкретной кампании, объявления и ключевого слова биддер выбирает самую дешевую позицию – неважно, третья это позиция, вторая или первая. Затем он сравнивает стоимость этой самой дешевой позиции с максимальной ставкой.
Если максимальная ставка меньше стоимости самой дешевой позиции спецразмещения, то расчет повторяется уже для гарантии – биддер выбирает самую дешевую позицию в гарантии. Если же стоимость самой дешевой позиции укладывается в предел максимальной ставки (которая равна среднерыночной стоимости клика по массиву), то биддер начинает бороться за позицию, добавляя 0.02 к стоимости самой дешевой позиции, после чего ваше объявление показывается на нужной нам позиции.
В завершение статьи хотелось бы, насколько это возможно, облегчить составление рекламных кампаний нашим читателям, предоставив в их распоряжение готовые списки минус слов, доступные для скачивания (станут доступны после публикации статьи на сайте 19 августа 2015 г – прим. редактора).
Приведенные минус слова собраны на основе анализа соответствующих выборок из базы MOAB. Приведены 200 наиболее часто встречающихся минус слов. Все минус слова приведены в 3 форматах: в формате регулярного выражения для Key Colletor, в формате, который сразу можно вставить в стоп-файл в интерфейсе кампании Яндекс.Директа, а также в формате, который используется для импорта стоп-слов в проект в программе «МегаЛемма».
Региональные списки (города) минус-слов для Белоруссии, России и Казахстана:
1. Банки
- кредит – формат Директа, формат регулярного выражения, формат Мегалемма
- займ – формат Директа, формат регулярного выражения, формат Мегалемма
- вклад – формат Директа, формат регулярного выражения, формат Мегалемма
2.Недвижимость
- аренда квартиры – формат Директа, формат регулярного выражения, формат Мегалемма
- недвижимость – формат Директа, формат регулярного выражения, формат Мегалемма
- ипотека – формат Директа, формат регулярного выражения, формат Мегалемма
3. Туризм
- туры – формат Директа, формат регулярного выражения, формат Мегалемма
- путевки – формат Директа, формат регулярного выражения, формат Мегалемма
4. Авто
- авто – формат Директа, формат регулярного выражения, формат Мегалемма
5. SEO и контекст
- seo – формат Директа, формат регулярного выражения, формат Мегалемма
- контекстная реклама – формат Директа, формат регулярного выражения, формат Мегалемма
- директ – формат Директа, формат регулярного выражения, формат Мегалемма
- продвижение сайта – формат Директа, формат регулярного выражения, формат Мегалемма
6. Телефоны
- samsung – формат Директа, формат регулярного выражения, формат Мегалемма
- apple – формат Директа, формат регулярного выражения, формат Мегалемма
7.Forex
- forex – формат Директа, формат регулярного выражения, формат Мегалемма
8. Авиабилеты
- купить авиабилеты – формат Директа, формат регулярного выражения, формат Мегалемма
9. Ноутбуки
- ноутбук – формат Директа, формат регулярного выражения, формат Мегалемма
10. Списки регионов
- Россия – формат Директа, формат регулярного выражения, формат Мегалемма
- Беларусь – формат Директа, формат регулярного выражения, формат Мегалемма
- Казахстан – формат Директа, формат регулярного выражения, формат Мегалемма




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}