

Для некоммерческих проектов
Понятие искусственной семантики
Существует множество определений термина «искусственная семантика», разные люди трактуют его совершенно по-разному. Поэтому, в первую очередь важно договориться о терминологии: что понимать под искусственной семантикой в данной статье?
Искусственная семантика – это семантическое ядро, сформированное искусственно, на основе изучения реальной семантики и формирования прогноза о том, как будут выглядеть поисковые запросы в реальности. Возможно, это не лучшее определение, поэтому обратимся к практическим примерам.
Итак, что же такое «прогноз, построенный на основе реальной семантики»?
Давайте представим ситуацию, в которой маркетолог работает с выборкой, собранной по запросу [ковш для погрузчика]. В этой ситуации стандартный алгоритм действий выглядит достаточно однотипно:
— собираем семантику из доступных источников (базы ключевых слов, Wordstat, подсказки, MOAB Pro, Suggest Pro)
— получаем некоторое количество расширенных поисковых запросов, содержащих [ковш для погрузчика]
— группируем и кластеризуем ключевые запросы
— получаем группы схожих запросов, на основе которых создаем посадочные страницы, контент, заголовки и прочее
В ходе кластеризации мы можем получить совершенно разные группы запросов, которые будут базироваться на неких реальных сущностях, вокруг которых группируется спрос в этой тематике:
[ножи для ковша погрузчика] + некоторое кол-во однотипных расширенных запросов
[ковш для погрузчика + %brand%] – т.е. ключевые слова, в которых пользователь уточняет, для какого именного бренда погрузчиков ему нужен ковш
[ремонт ковша для погрузчика] + некоторое количество однотипных расширенных запросов
[емкость/вместимость ковша для погрузчика] + некоторое количество однотипных расширенных запросов
Так или иначе, очевидно, что в рамках каждой тематики расширенные запросы формируются вокруг более мелких «подтем», которые, в свою очередь, зависят от тех реальных сущностей (ножи, ремонт, бренды), которые востребованные в оффлайне.
И, в случае тематики [ковш для погрузчика], мы не можем «заранее» предсказать или спрогнозировать эти сущности, не будучи специалистом по погрузчикам. Единственный способ выделить возможные пользовательские проблемы – получить статистически достоверный массив семантики, а затем выполнить ее кластеризацию.
Однако, в некоторых тематиках дело обстоит по-другому. Иногда у маркетолога появляется возможность, на основе изучения и анализа статистически достоверной выборки, спрогнозировать, как будут выглядеть запросы и спроектировать сайт и маркетинговую стратегию на основе этих данных.
Классический пример – туризм, в частности, и вообще все, что так или иначе базируется на «географических» запросах, связанных с перебором стран/городов как набора переменных:
а) Список стран на сайте 1001Тур
б) Для каждой конкретной страны контент довольно похож, различается только страна и собственно сами туристические предложения. Сравните, например, страницы про Мексику и Абхазию:
- одинаковый, маленький, «неуникальный» в классическом смысле слова текст, от страницы к странице подменяется только страна. Адепты карго-культа о расчете количества употреблений каждого конкретного слова на странице могут испытать неприятные ощущения в области спины
- все title созданы по единой схеме: <title>%страна% — туры, цены на отдых в Абхазии 2016 вылет из Москвы: путевки, новости, погода, курорты и достопримечательности — 1001 Тур. </title>
- все h1 созданы по единой схеме: Туры в %страна% 2016 из Москвы
- активно эксплуатируется тема прогнозирования запросов под «будущий» трафик.
Например, вряд ли кого-то удивят страницы формата:
Горящие туры за картошкой в раскладке по месяцам: страница 1, страница 2, страница 3
При этом самих по себе предложений горящих туров в Белоруссию на сайте нет, что однозначно говорит о том, что страницы были просто склонированы по шаблону, а затем на них были выведены туры «по соответствию» в поле «страна».
При этом страницы без предложений из индекса убирать не стали, что однако, не помешало им занять место в ТОПе Яндекса.
Однако многих, вероятно, может удивить наличие в индексе вот таких страниц:
Маркетологи 1001Тур грамотно клонируют страницы не только по переменным %город% и %страна%, но и по переменным %месяц%, %год%, так как знают, что даже создав «пустую» страницу без туров под «будущее» можно застолбить место в выдаче уже сейчас. Фактически, страницу с возрастом 1-2 года, появившуюся задолго до появления запроса [туры гоа 2017], в каком-нибудь условном феврале-декабре 2017 будет очень тяжело «подвинуть» в топе.
Таким образом, мы увидели главное – запросную базу в некоторых тематиках при необходимости можно разложить на составляющие (=переменные), спрогнозировать значение этих переменных, а затем получать как органический, так и контекстный трафик на основе этих переменных.
Искусственная семантика и уникальность текста
Зачастую использование искусственной семантики для получения органического трафика сталкивается не столько с какими-либо техническими или организационными трудностями, сколько с огромным набором предрассудков и предубеждений, существующих в головах оптимизаторов.
Один из ключевых предрассудков – так называемая уникальность текста. Уникальность текста в трактовке обычного оптимизатора – это уникальный набор слов. Уникальность набора измеряется при помощи специальных программ, использующих метод шинглов. Однако, когда речь идет об искусственной семантике, подразумевается, что тексты на всем сайте будут одинаковыми – на каждой конкретной странице будет подменяться только набор заранее заданных переменных – город, месяц, адрес, год, и так далее.
Чаще всего это вызывает подлинный испуг: как!?? Ведь тексты будут неуникальными!
Тут необходимо сделать разъяснение: уникальность текстов, измеренная по методу шинглов давно игнорируется Яндексом в любых тематиках, для Google существуют как позитивные (в большинстве случаев), так и негативные примеры, в зависимости от тематики. Оговорюсь, что под позитивными и негативными примерами я понимаю не столько сами позиции (неинформативная метрика), сколько получение или неполучение значительного количества трафика с поисковой системы при использовании как бы неуникальных текстов.
Еще раз: проверка текста на уникальность, которую стандартный оптимизатор выполняет при помощи Advego Plagiatus (или любого аналога) – не имеет смысла. Грамотное построение сайта и взаимодействие с поисковой системой в рамках ее правил может дать вам большое количество трафика, даже при использовании на 100% скопированного контента, «шаблонного» контента с использованием переменных или комбинации этих приемов.
Что же понимают поисковые системы под «уникальным текстом»?
Поисковые системы давно и хорошо умеют две вещи:
а) отслеживать взаимодействие пользователя с конкретным документом
б) составлять «фактическую» выжимку из документа
Работу «фактической» выжимки можно отлично видеть на примере Яндекс.Новостей, когда документы, описывающие одно и то же событие разными словами, приводятся к одному знаменателю: Выставку «Ван Гог. Ожившие полотна 2.0» продлили до 8 марта.
На поиске отрабатывает комбинация указанных факторов: с одной стороны, важно насколько успешно документ решает пользовательскую проблему, с другой – насколько уникален набор фактов, предложенный пользователю по его проблеме в данном документе.
Исходя из своего опыта, могу сказать, что сам не проверяю на уникальность тексты, которые пишут для меня копирайтеры. Однако, работая с постоянным набором копирайтеров и редакторов, даю им четкую установку: любое слово и фраза в тексте должно быть употреблено потому, что сообщает пользователю некий важный факт, связанный с его проблемой, ради решения которой он посещает страницу.
Ниже будет показано, что «неуникальные» тексты могут привлекать значительное количество трафика из поисковых систем – и при этом их, так называемая «неуникальность», не приводит к каким-либо негативным последствиям.
Искусственная семантика для некоммерческих проектов
В первую очередь представлю вниманию читателей реальный кейс проекта, построенного на искусственной семантике, а затем на примере расскажу, как сделать «проект» сайта на искусственной семантике своими руками и с минимальными затратами.
Кейс: сайт тематики «Отопление», некоммерческий сезонный трафик, 90% трафика – поисковые системы, примерно равное распределение между Yandex и Google. Сайт привлекает траффик по геонезависимым запросам. В индексе 3000 страниц (5526 загружено роботом, 3053 – страниц в поиске).
Для всех 3000 страниц используются 4 шаблона текста, тайтлов, дескрипшнов и h1. В шаблонах подменяется только город и область. Расходы на контент для этого сайта составили около 3000 рублей. Монетизация – открутка рекламы, как Adsense, так и прямые баннеры наших коммерческих партнеров. Ссылки не покупались.
Пик сезона, с точки зрения спроса, – конец весны, и затем плавный рост до октября-ноября:
На этом скриншоте из Метрики мы видим:
1. Суммарная посещаемость – почти 300 000 посетителей менее чем за 3 месяца
2. Пиковые значения – 12000 и 6000 посетителей в сутки из Google и Yandex соответственно
3. Отказы – чуть более 10%, то есть очевидно, что несмотря на «шаблонный» контент, пользователи вовлечены во взаимодействие с сайтом
4. Время просмотра – чуть более минуты в среднем, в зависимости от поисковой системы
На данный момент сайт в индексе, посещаемость на уровне 500 посетителей\сутки, плавно начинает расти в преддверии весеннего сезона. К сожалению, я не могу показать URL сайта, но предлагаю рассмотреть на простом примере алгоритм построения подобных сайтов.
Итак, возьмем для примера тематику «Бани». Тематика достаточно простая, в качестве переменной в запросах используется много географических обозначений. Предположим, что в итоге мы хотим создать сайт-агрегатор информации о банях и саунах в регионах России. Ниже будет показан упрощенная общая схема действий – в данном случае не преследуется цель сделать лучший в мире сайт о банях, важно лишь показать общий принцип обработки семантики на практике.
Будем придерживаться следующего плана:
1. Спарсим и проанализируем семантику
2. Разработаем структуру сайта в Excel на основе данных анализа
3. Закажем контент для страниц категорий и страниц описаний собственно банных комплексов
Парсинг и анализ семантики
Возьмем выборку из обновленной 6-миллиардной базы MOAB Suggest Pro (аккуратно, выборка с доп.данными – около 60 МБ), это все запросы с вхождением «Бани» с точной частотностью более 1, для региона «Россия».
Всего найдено 282 995 запросов.
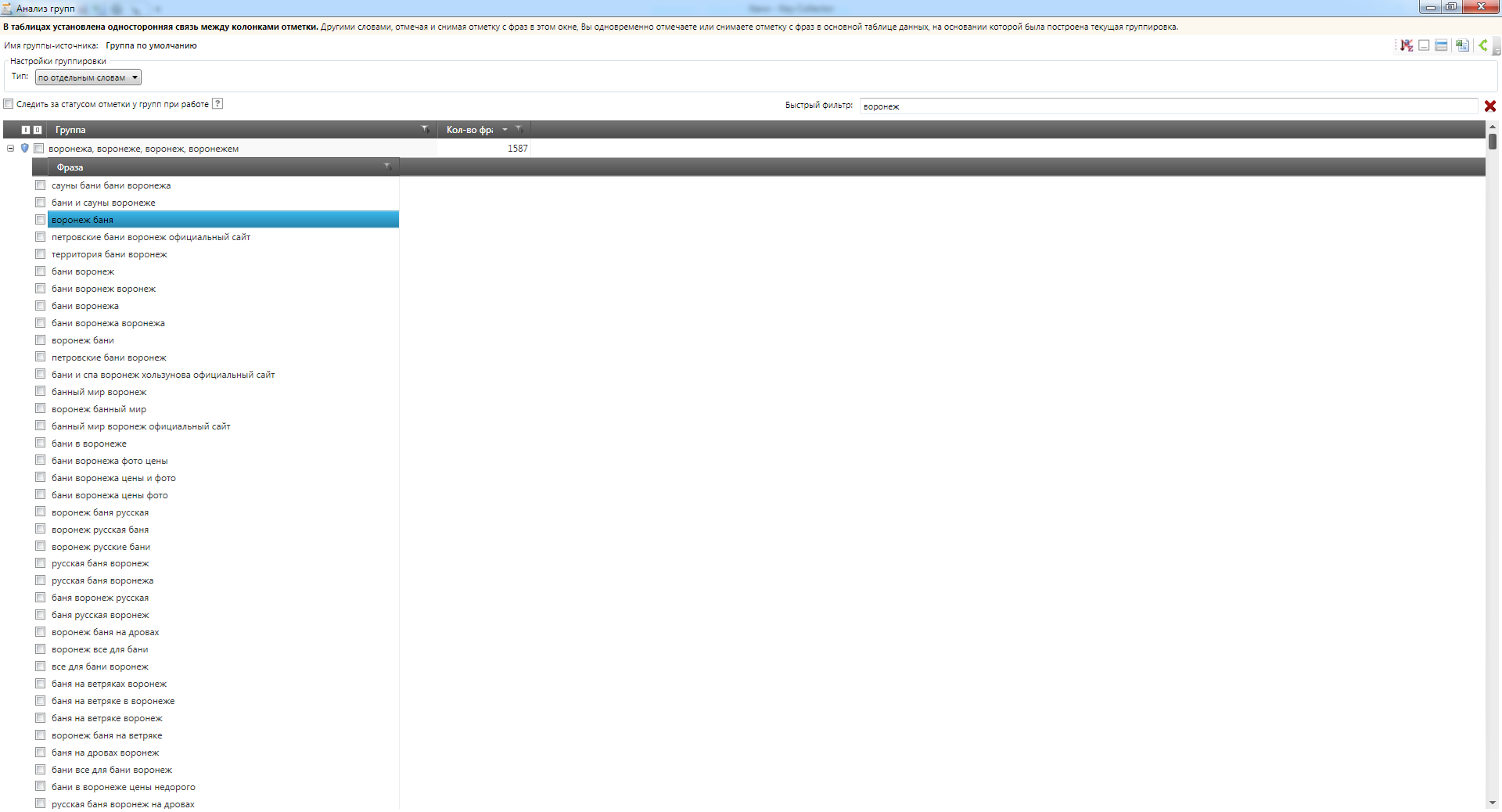
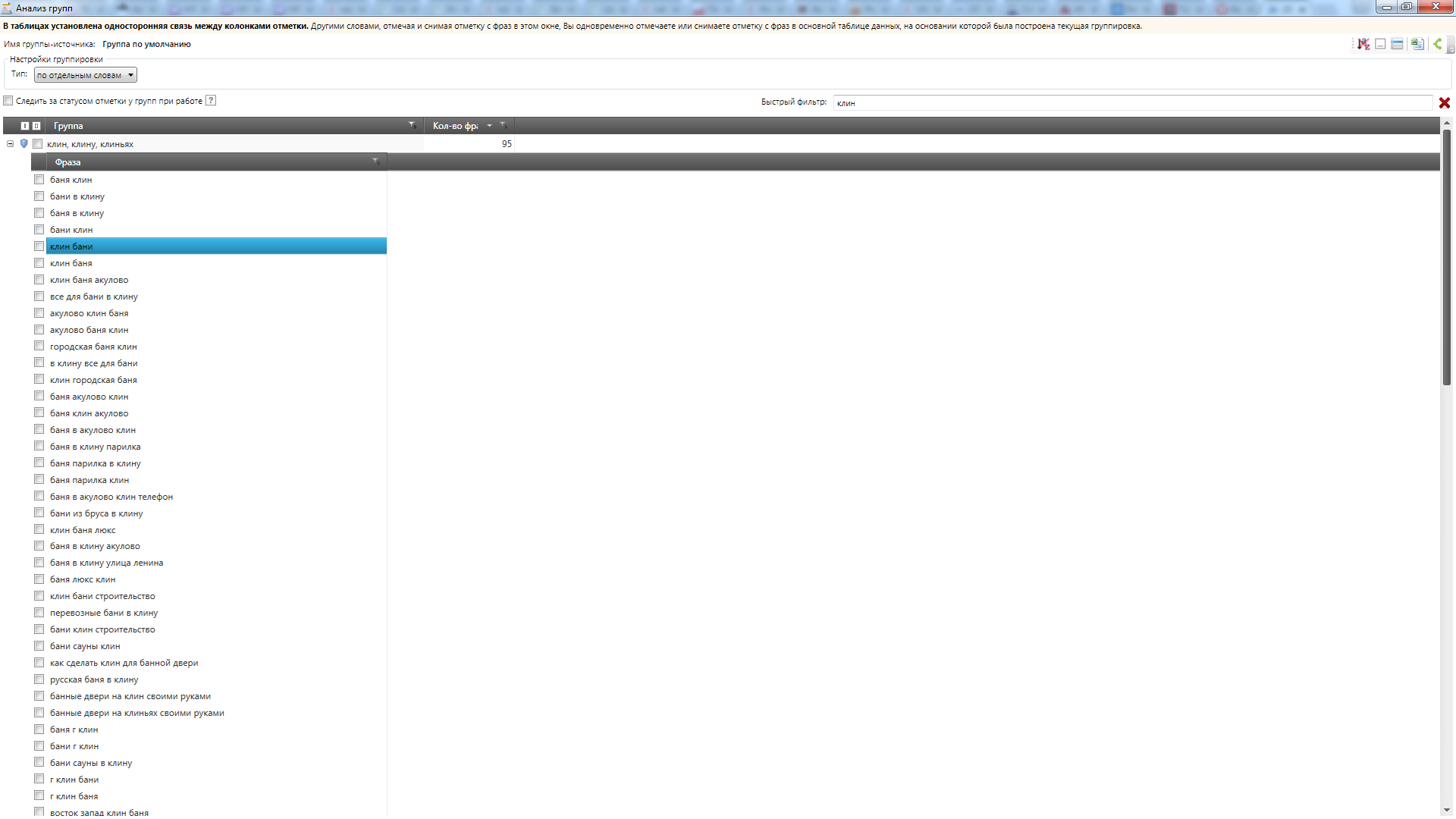
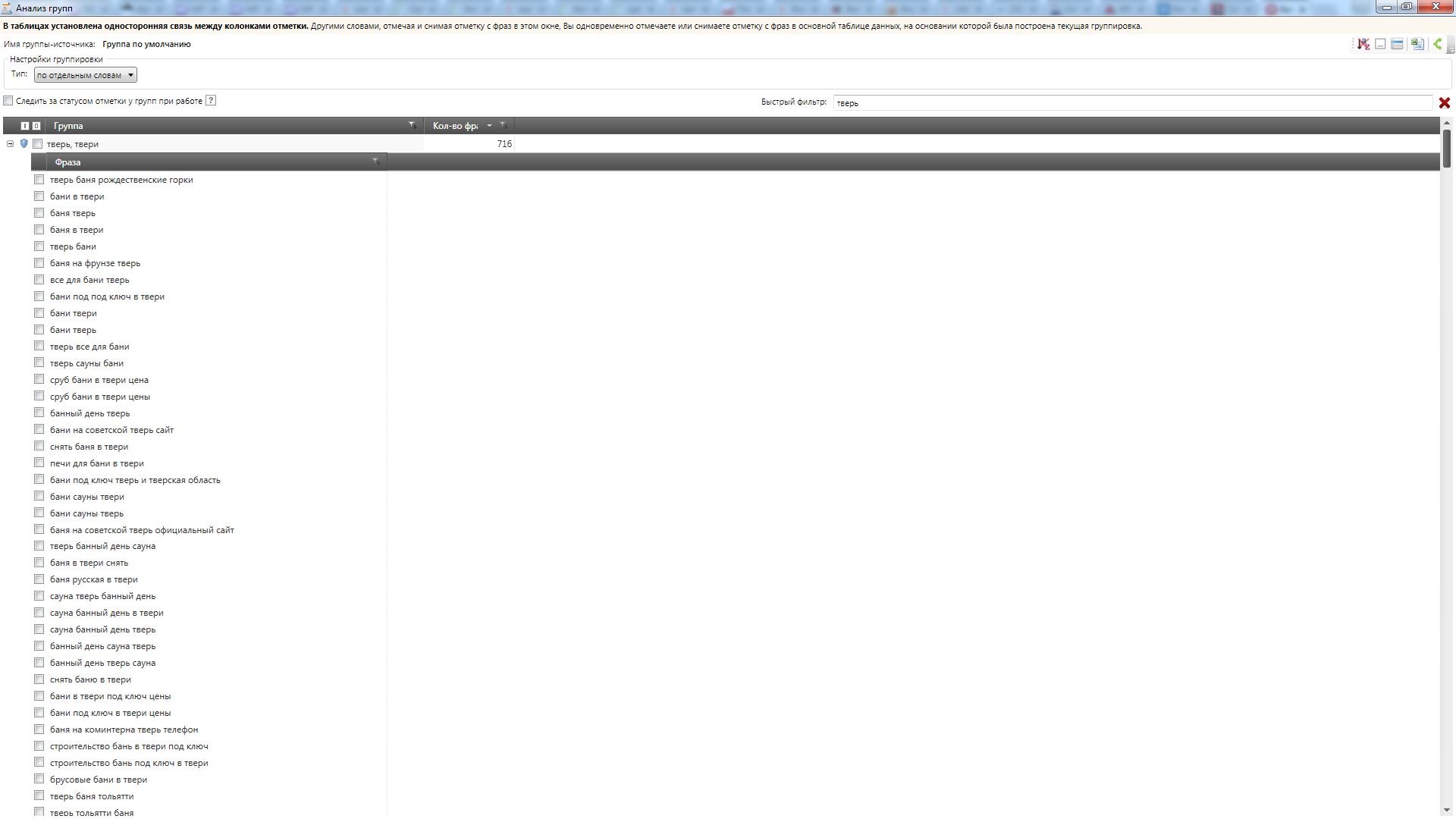
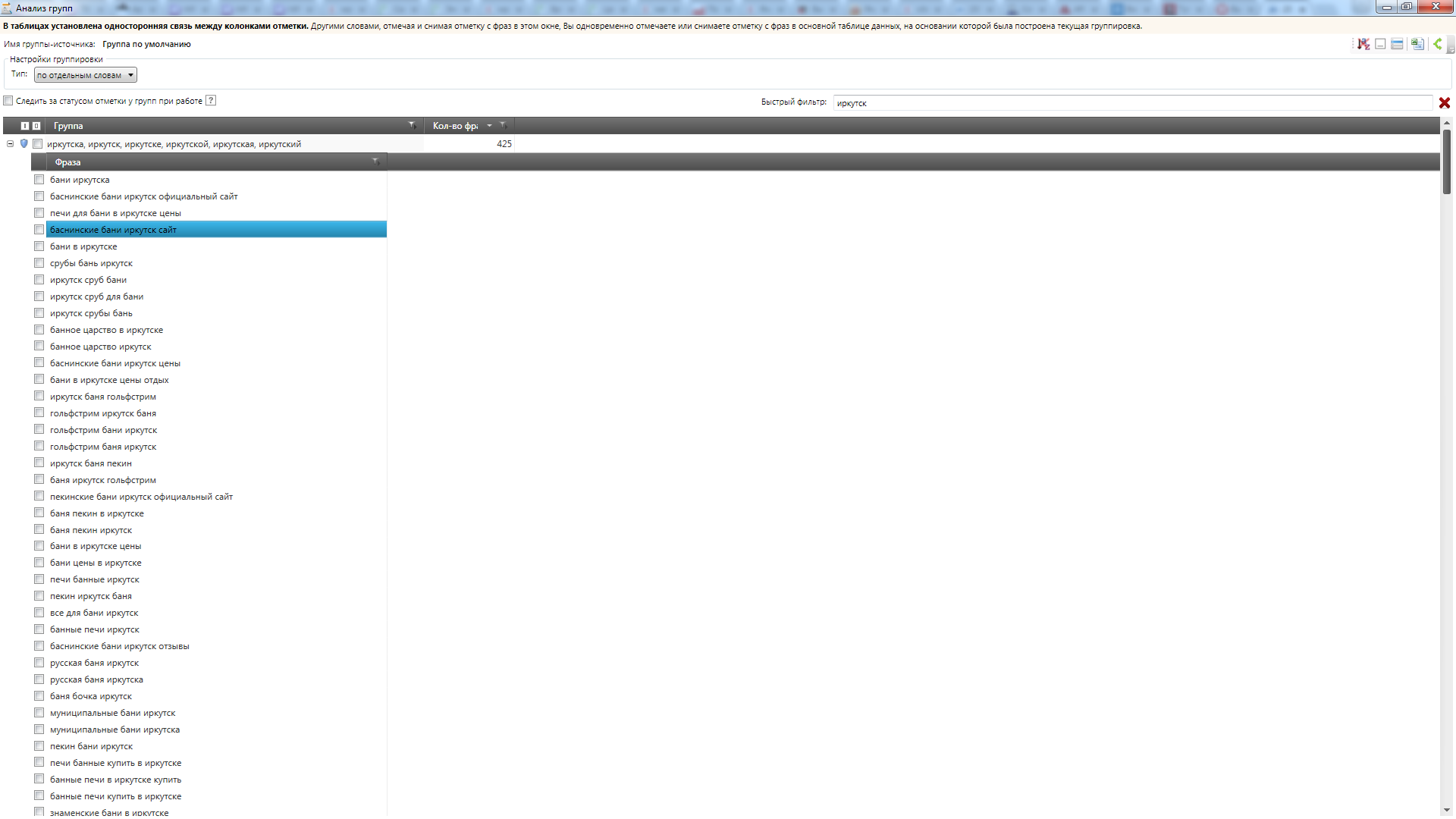
Анализ файла в инструменте «Анализ групп» в Key Collector показывает, что выборка в высокой степени насыщена однотипными региональными запросами вида:
[бани + %что-то еще% + %регион%]
(Скриншоты: Воронеж, Клин, Тверь, Иркутск).
Это позволяет нам утверждать, что данная тематика подходит для наших целей: список регионов – это набор заранее известных переменных, а что скрывается под %что-то еще% — как раз сейчас мы и выясним.
Разработаем структуру сайта в Excel на основе данных анализа
Во-первых, сравним несколько выборок по запросам с городами: [бани воронеж], [бани самара], [бани спб]. В ходе сравнения нам необходимо выполнить кластеризацию – проще всего это делать при помощи инструмента «Анализ групп» в КК, но можно воспользоваться и любым другим удобным методом кластеризации. Наша задача – сравнивая кластеризованные выборки, найти группы пользовательских интересов, востребованные вне зависимости от города, то есть вычислить наиболее популярные «добавки», то самое «что-то еще», о котором мы говорили выше — [бани + %что-то еще% + %регион%]
Даже в результате поверхностного анализа выявляется следующий список групп:
— бани на дровах
— бани с вениками
— бани с бассейном
— бани со спа
— общественные бани
— бани с бочкой
— бани турецкие
— бани римские
— мобильные бани
Таким образом мы получили так называемый список категорий второго уровня. Пока оставим эту информацию в стороне и внимательно посмотрим, какие слова часто употребляются вместе с названием любой случайной бани, то есть вычислим наиболее стандартные «добавки» для формулы — [%название бани% + %город% + %что то еще%]
Для этого нам надо взять статистически достоверный массив запросов, состоящий только из названий бань – а затем снова кластеризовать его. В результате подобной операции выявлено, что чаще всего вместе с названием бани и городом употребляют следующие словосочетания:
— официальный сайт
— цена, прайс лист
— фото
— отзывы
— адрес
— телефон
— часы работы
Эта информация поможет нам при создании собственно каталога бань.
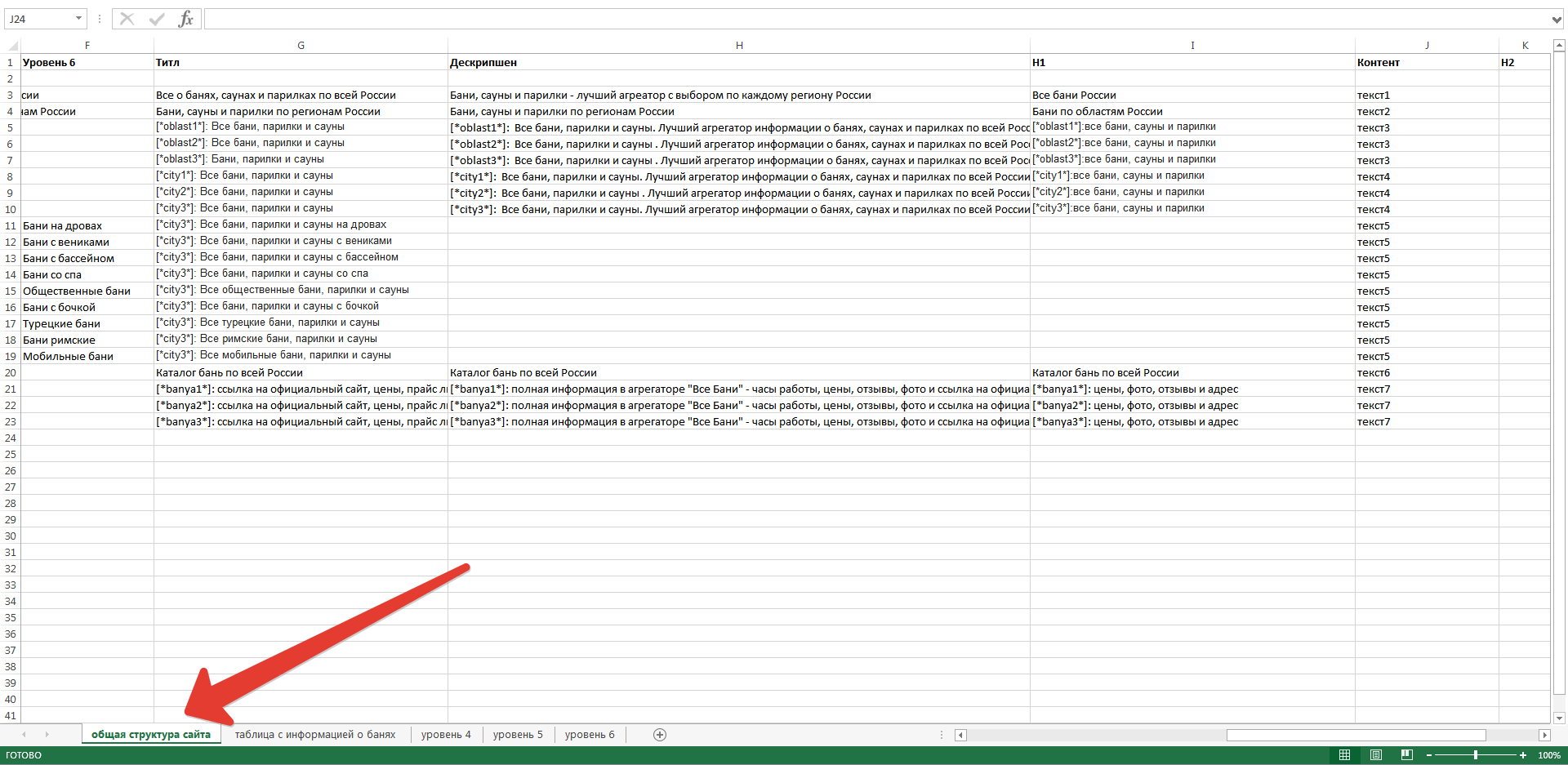
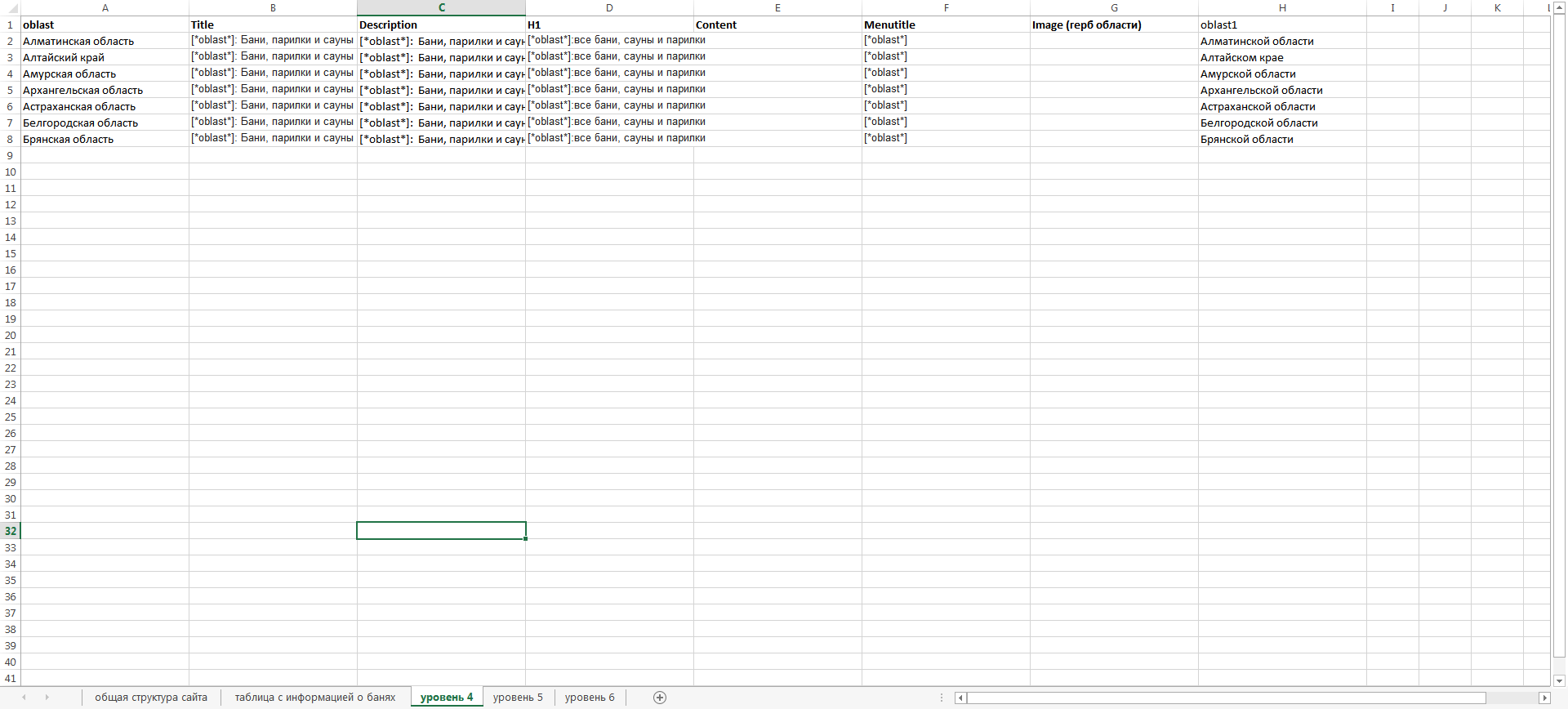
Теперь у нас есть вся информация, необходимая нам для создания структуры сайта. Полученную информацию можно преобразовать в файл плана сайта, который в Excel выглядит вот так.
Давайте вместе разберем этот файл более подробно, а также более подробно разъясним зачем нам понадобилось проводить анализ семантики, описанный выше.
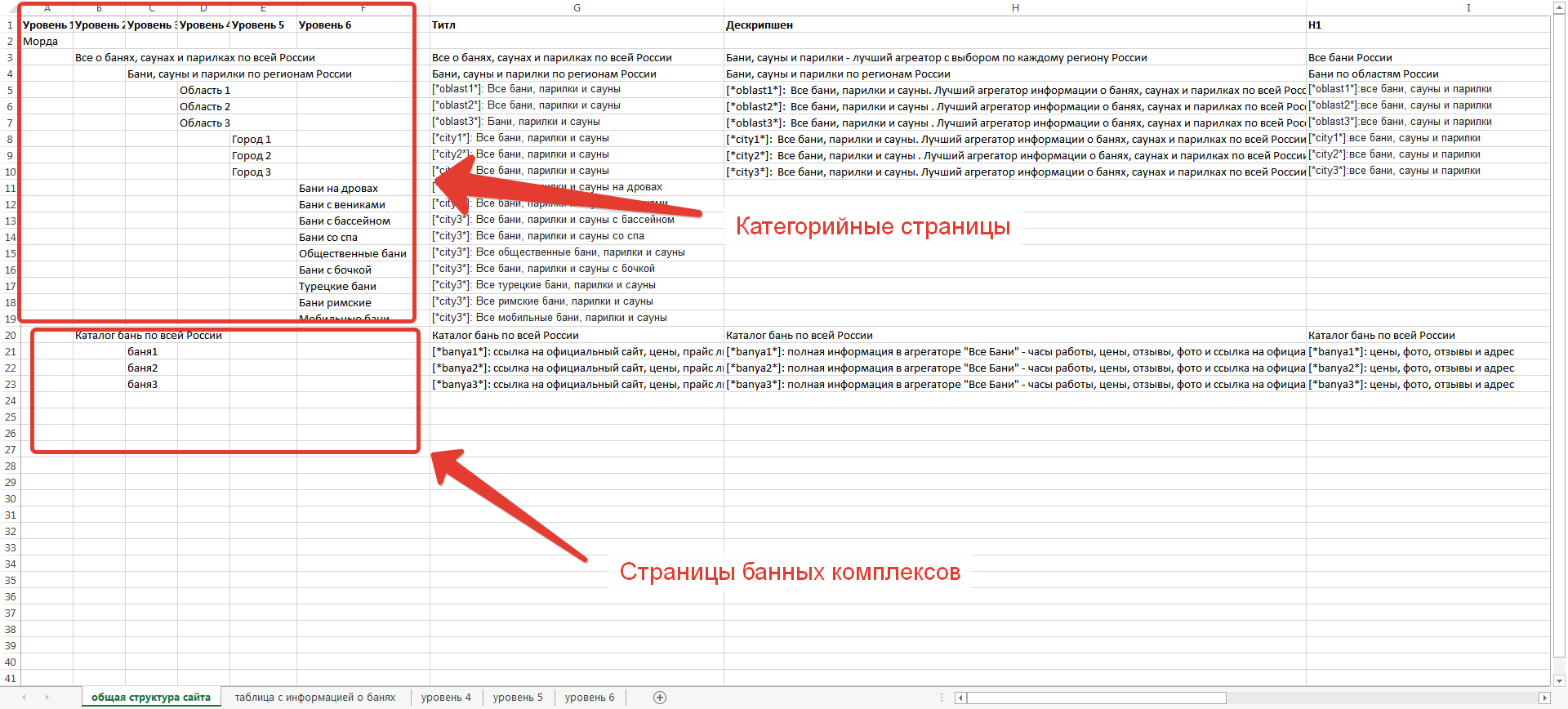
Вкладка «Общая структура сайта»
На этой вкладке рассмотрена общая структура проектируемого сайта. Все страницы разбиты по уровням вложенности:
Обратите внимание, что существует два каталога второго уровня, дочерних от главной страницы:
— каталог с категорийными страницами
— каталог со страницами собственно банных комплексов
При помощи нехитрых скриптов, имеющихся в большинстве современных CMS, на более позднем этапе мы осуществим автоматический вывод релевантных банных комплексов на каждой странице.
Особо хотелось бы обратить ваше внимание на текстовые параметры сайта: тайтл, дескрипшн и H1 – они используют переменные %область%, %город%. Во всех текстовых тегах упомянуты синонимы слова «баня» — «парилка» и «сауна», для сбора большего количества низкочастотного трафика в соответствующем городе:
Важно правильно понимать, что на данной схеме дается лишь ограниченное количество страниц, чтобы схематически показать общую структуру сайта.
На боевом варианте сайта будет взята база всех областей РФ (а, возможно, и ex-СНГ), база всех городов в этих областях, будет создано соответствующее количество страниц.
Наконец, самое важное – столбец «Контент»:
Под словом «текст№ххх» в данном столбце подразумевается отдельный шаблон текста – то есть, как не трудно увидеть, всего на сайте будет использоваться 7 шаблонов текста. В самих шаблонах будут использоваться уже знакомые нам переменные – город, область, название бани.
Не рекомендуется делать тексты очень большими – в данной ситуации будет вполне достаточно объема в 1500-2000 символов, однако, постарайтесь заказать шаблон действительно профессиональному копирайтеру, возможно, бывшему журналисту – так, чтобы текст был на самом деле увлекательным, интересным, наполненным полезной информацией.
Почему именно 7 шаблонов? Как видно, используется отдельный шаблон на каждом уровне – ввиду того, что каждый уровень – это как бы немного другая реальная сущность, несущая немного другую смысловую нагрузку, поэтому лучше использовать шаблоны максимально адаптированные для каждого уровня в отдельности.
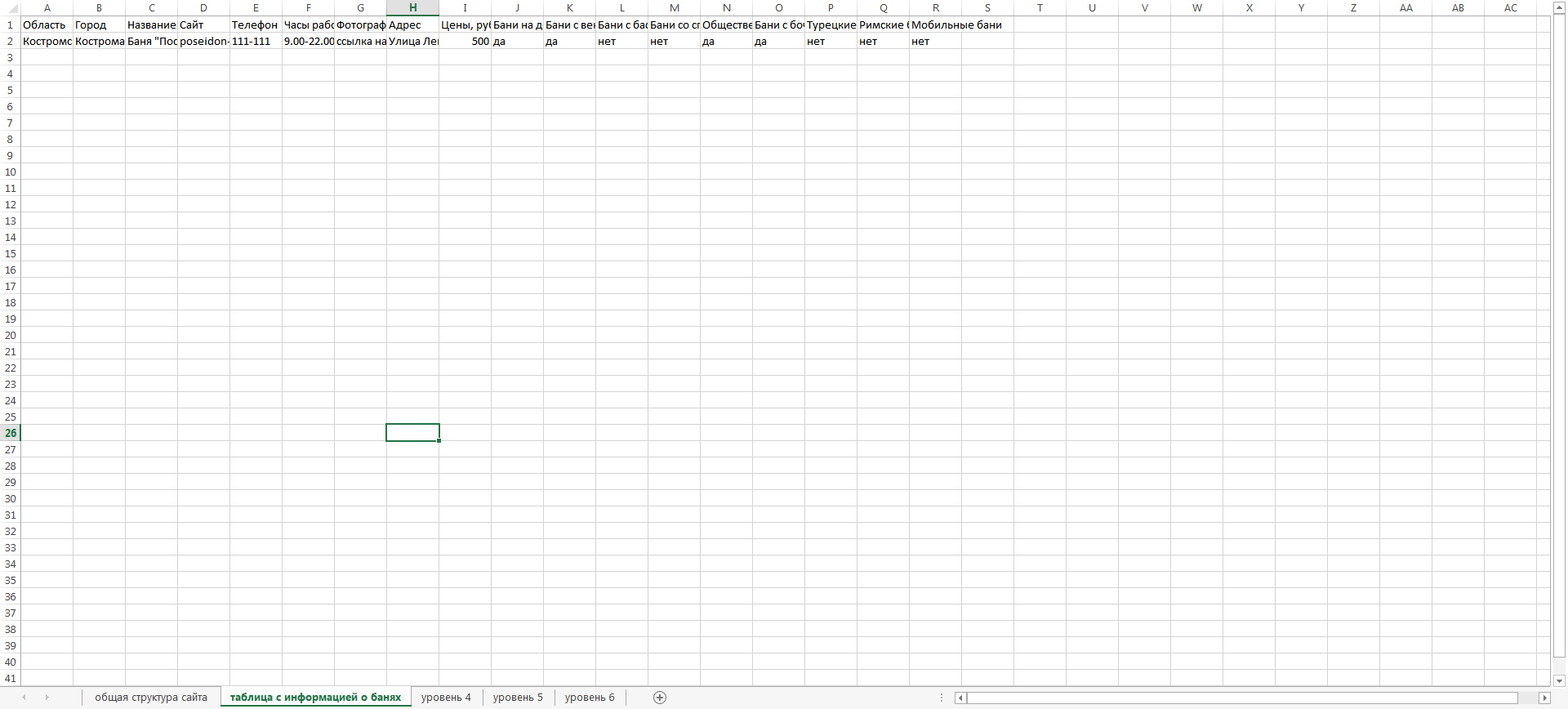
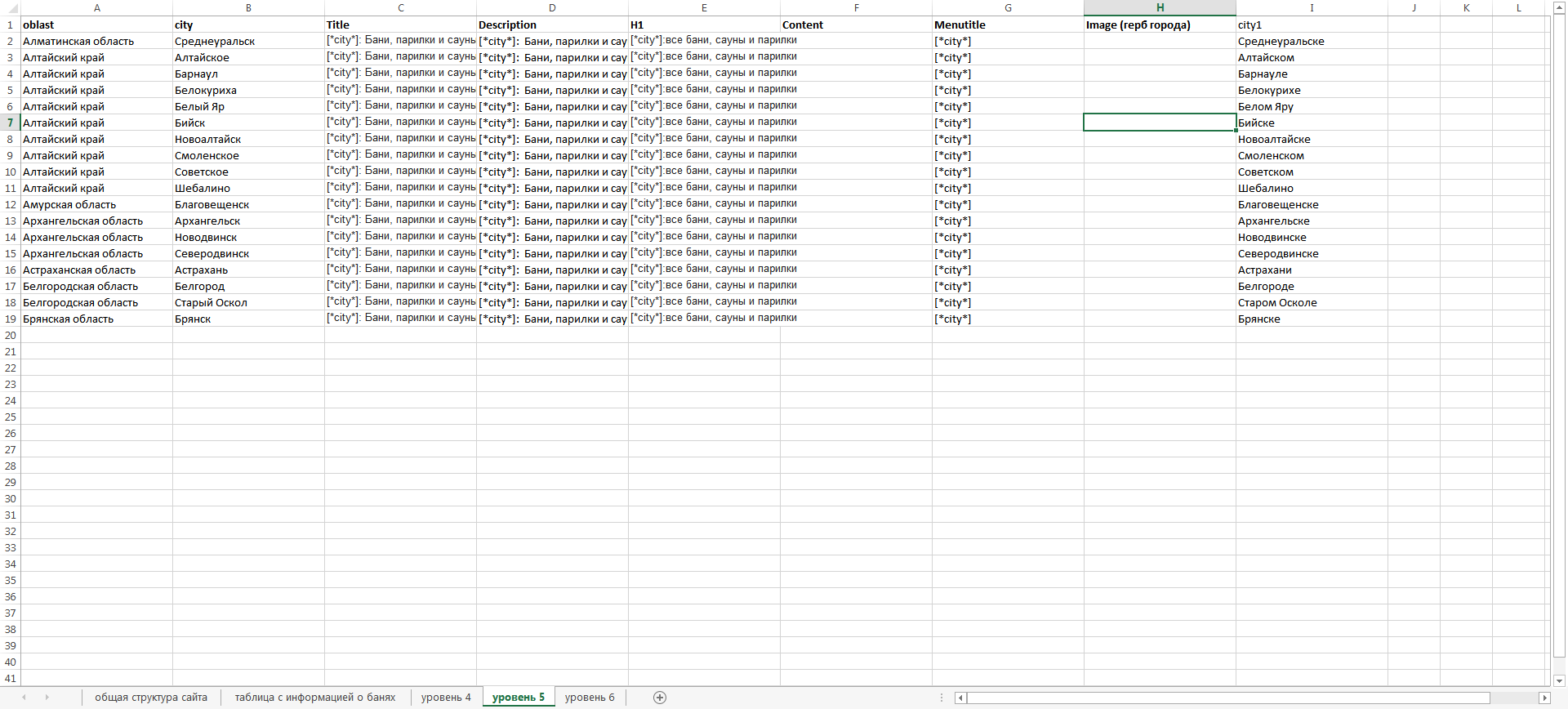
Вкладка «Таблица с информацией о банях»
В этой таблице приведены поля, которые необходимы нам в каталоге бань и саун, а также для примера выполнено заполнение этих параметров по одной выдуманной бане.
Итак, параметры в столбцах A-I появились в таблице неспроста:
Именно эти слова, как показывает наш анализ, чаще всего употребляют пользователи вместе с названием некоей случайно бани, а значит – наша задача – дать ответ на все вопросы вида — [%название бани% + %город% + %что то еще%].
В данном конкретном случае это означает, что в нашем огромном каталоге бань по каждой бане должна быть информация по сайту, телефону, часам работы, адресу бани, а также ее фотографии.
Откуда взять этот контент?
Здесь вариантов масса, в зависимости от того что предпочитаете лично вы: можно заказать программисту скрипт парсинга некоего публичного источника, либо воспользоваться базами данных организаций, которые в изобилии можно купить или скачать в интернете бесплатно в виде Excel. Там есть все эти данные, и не составит труда перенести их в нашу таблицу.
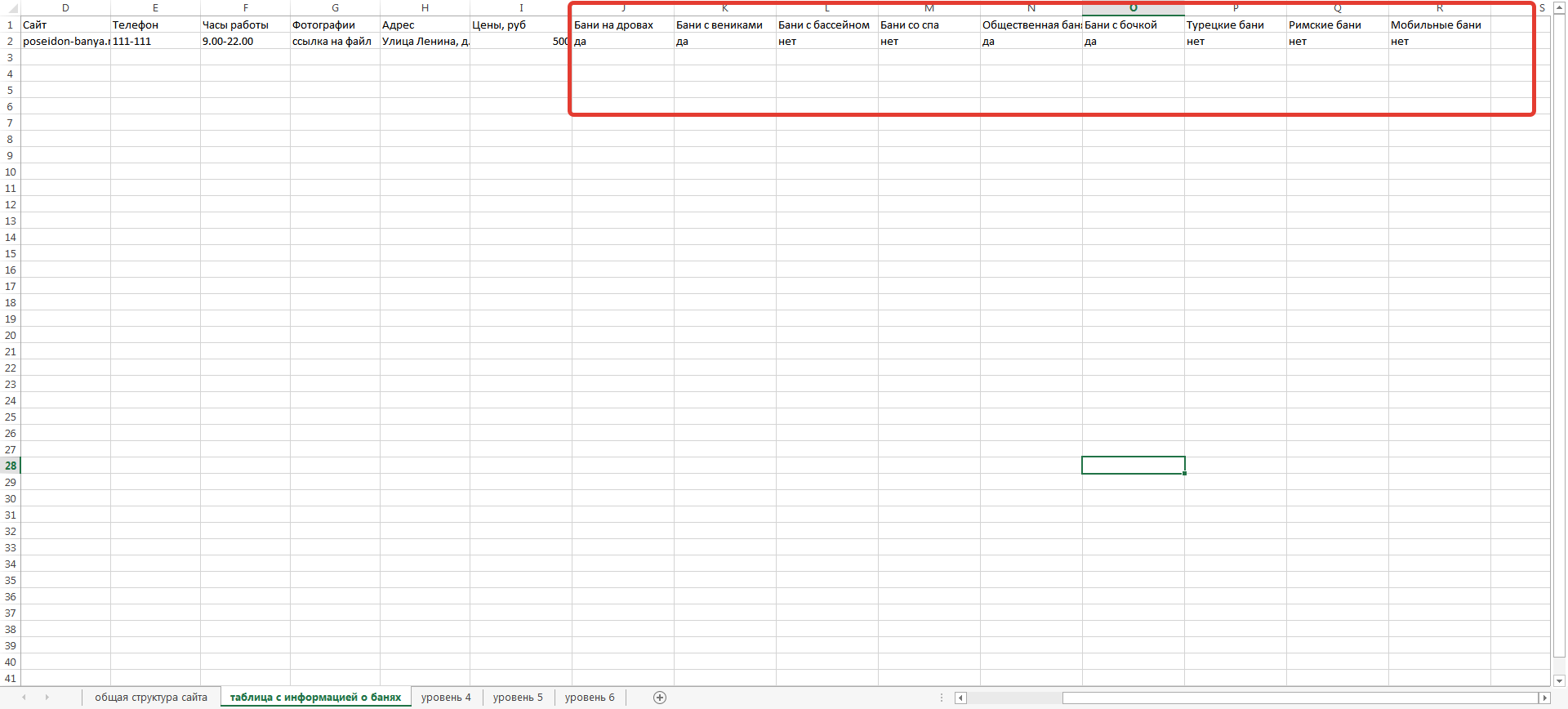
Несколько труднее обстоит дело со столбцами I-S.
Как вы помните, категоризация на уровне 6 в общей структуре сайта подразумевает создание страниц вида:
Чтобы решить эту задачу, нам необходимо сделать две вещи:
— создать поле «тип бани» на самой категорийной странице и внести туда значение drova=true или же veniki=false
— создать аналогичное поле на странице собственно бани, чтобы затем автоматически вывести все релевантные бани с фильтрацией по городу, области и типу на соответствующей странице.
То есть, например, к выводу бань на странице «Бани на дровах в Красноярске» будет автоматически применен фильтр city=Krasnoyarsk и drova=true.
Если с информацией о городе мы уже разобрались, то все несколько сложнее с категоризацией второго уровня. Здесь наиболее оптимальный путь – выдать таблицу с заполненными полями A-I фрилансеру (а лучше нескольким) и попросить их расставить значения «да-нет» в соответствующих полях за умеренную плату.
Поверьте, расходы будут невелики, особенно с учетом того что фриланс сейчас – это рынок покупателя, а не продавца.
Вкладки «Уровень 4,5,6»
Наиболее остро стоящая проблема для подобных сайтов на искусственной семантике – создание страниц.
90 областей + (1000 городов * 9 категорий) + как минимум несколько тысяч страниц с описанием банных комплексов = итого 4-5 тысяч страниц вам гарантированы.
Проблема создания страниц решается достаточно просто – для любой популярной CMS вы без труда найдете скрипт загрузки страниц из xlsx или csv. В этом представлении, 1 строка = 1 страница.
Давайте посмотрим, что происходит на наших вкладках с точки зрения массовой загрузки? На вкладке «Таблица с информацией о банях» — все просто. Сколько строк, столько и страниц, каждая страница обладает 18 полями с расширенной информацией о бане. Однако у нас остались еще категорийные страницы – с ними все то же самое, просто их нужно представить в аналогичном построчном виде.
Уровень 4 «Области»; уровень 5 «Города»; уровень 6 «Категории внутри города»
В таблицах представлено ограниченное количество городов и областей исключительно для понимания процесса. Значения переменных в таблицах берутся из столбцов, существующих в этой же таблице. В этой связи – можно обратить внимание на столбец H в таблице «уровень 6», где значение переменной city приводится в родительном падеже для использования в заголовке.
В итоге, можно резюмировать, что создание некоммерческих/информационных проектов на основе искусственной семантики состоит из нескольких этапов:
— сбор семантики и выявление в ее структуре прогнозируемых переменных (город, месяц, отель, курорт, баня, заправка и пр.)
— составление структуры сайта на основе информации о популярных переменных
— создание шаблонных текстов для каждого уровня
— представление текстового контента ( в т.ч. и текстовых тегов) в виде Excel-таблиц с переменными в разбивке по уровням
— замена переменных их реальными значениями на этапе обработки в Excel или после загрузки в CMS (нежелательно это делать при генерации страницы – излишняя нагрузка на базу, тогда как на практике такой контент редактируется редко и пользы и удобства от переменных немного)
— автоматизация загрузки контента в движок
Вторая часть статьи, которая рассматривает применение искусственной семантики для коммерческих проектов – для получения как контекстного, так и органического трафика.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}