

Могут ли роботы уволить PPC-специалиста?
Об автоматизации маркетинга не говорит только ленивый. Бизнес-процесс рядового интернет-маркетолога на сегодняшний день собирается как конструктор – из 10-15 сервисов и десктопных программ, автоматизирующих все, что только возможно алгоритмизировать.
Ключевой вопрос этой статьи: в какой мере пресловутая автоматизация может быть использована при создании продаж на основе контекстной рекламы?
На самом деле вопрос это достаточно болезненный. Диджитал в целом и контекстная реклама в частности – это молодой, неконсолидированный рынок, не имеющий ни единых правил игры, ни полного цикла автоматизации для решения наиболее трудоемких задач по созданию полного цикла продаж. Какие-то этапы (управление ставками) автоматизированы в высокой степени – просто потому что могут быть полностью алгоритмизированы. Другие этапы, требующие сложной алгоритмизации и сравнительно высокой квалификации оператора автоматизированных программ (создание файла стоп-слов), большинство маркетологов выполняет вручную или на основе костылей той или иной степени пригодности.
Этот текст – моя попытка разобраться в этом вопросе.
- Что можно автоматизировать с приемлемыми потерями качества в контекстной рекламе, а что невозможно доверить роботу?
- С какими узкими местами столкнется руководитель агентства или in-house, перед которым стоит задача производства больших объемов контекстной рекламы?
- Где автоматизация рентабельна и необходима, а где дешевая рабочая сила даст фору самому совершенному ПО?
Итак, давайте для начала разберемся, из каких этапов состоит PPC-лидген, и попробуем по отдельности проанализировать каждый из них.
Время собирать слова: роботы и семантика
Сбор семантики – первый этап любой маркетинговой кампании, будь то SEO или PPC. Здесь автоматизация достигла поистине высокого уровня: доступны разнообразные источники ключевых слов (Wordstat, подсказки, собственные Метрики) и множество сервисов-надстроек над ними: базы, SaaS парсеры и десктопные приложения. В общем, если контент есть в интернете – его спарсят, и то же самое касается ключевых слов, которые так нужны маркетологам.
Однако обратная сторона медали – подбор самих по себе базисных запросов, расширения к которым собираются при помощи автоматизации.
О чем именно речь?
В ситуации, когда специалист использует некую автоматизацию сбора семантики, он вынужден отталкиваться от т.н. базисных запросов – если продаем пластиковые окна, то и базисный запрос будет такой же – «пластиковые окна», этот запрос поступит на вход к сервису/программе сбора семантики. В ответ специалист получает 100500 запросов формата «пластиковые окна + что-то еще», впечатляется от количества полученной семантики и с чувством выполненного долга приступает к обработке запросов.
И вот здесь возникает несколько вопросов, автоматизированных ответов на которые не существует.
Первый из них – сбор синонимов и переформулировок
С пластиковыми окнами все понятно и просто. Хотите пример посложнее? Вот пример базисных запросов для компании, занятой в сфере подготовки сжатого воздуха для работы на промышленных предприятиях (приведена часть СЯ по одному из разделов):
абсорбционная осушка
адсорбционная осушка
осушка компрессора
адсорбционный осушитель
безнагревный осушитель
влагоотделитель +для компрессора
водосепаратор
горячая регенерация
детектор масляного тумана
мембранный осушитель
нагревный осушитель
обработка воздуха
осушитель +для компрессора
осушитель воздуха компрессора
осушитель сжатого воздуха
осушка воздуха
осушка газа
очистка конденсата
подготовка воздуха
промышленные осушители
рефрижераторный осушитель
система сжатого воздуха
стерильная фильтрация
удаление конденсата
ультрапак
установка осушки
фильтры сжатого воздуха
фреоновая осушка
холодная регенерация
охладители сжатого воздуха
Каждый базисный запрос – это якорь, на основе которого будут собраны расширения. На основе расширений затем будут построены контекстные рекламные кампании. Однако для того чтобы собрать сами базисы – необходим ручной труд специалиста, включающий в себя работу с контентом/сайтом заказчика, «правой» колонкой Wordstat, синонимами на выдаче, сервисами анализа конкурентов и пр.
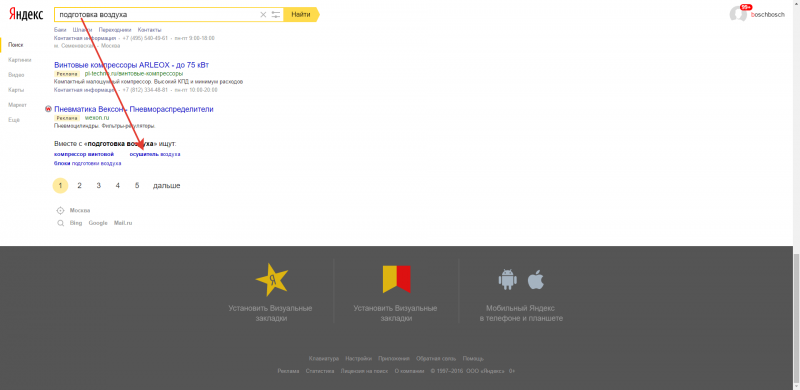
Переформулировки на выдаче – важный инструмент сбора СЯ в незнакомой теме
Конечно, столь подробный сбор синонимов на данный момент не является стандартом отрасли ни для подрядчиков по SEO, ни для подрядчиков по контексту. Большинство из них до сих пор работают по схеме:
– Что продаете?
– Окна!
– Отлично, вот вам 100 (200, 300, 500…) запросов про пластиковые окна и счет на 50 000!
Тем не менее, если мы говорим о том «как надо делать», а не о том «как делают», то мы вынуждены признать:
В значительном количестве ниш (из опыта – не менее половины) сбор СЯ представляет из себя долгую и трудную работу с базисами, автоматизации для решения этой задачи пока не существует.
Приведенный выше кейс – абсолютно реальный, в полном СЯ для этой компании около 100 базисов, на их сбор ушло полтора дня специалиста вместе с согласованием с заказчиком. Но в моем опыте есть кейсы, когда только (sic!) сбор базисов требовал слаженной работы нескольких специалистов в течение 2-3 недель в очень плотном контакте с заказчиком, а полученное ядро включало в себя несколько тысяч строк. Речь, естественно, идет только о тысячах базисов, обладающих ненулевой частотностью по Wordstat и не «пересекающихся» друг с другом. По каждому из этих тысяч в дальнейшем было собрано тысячи расширений.
И здесь мы сталкиваемся с второй проблемой: полнота или трудозатраты?
Звучит непонятно?
Окей, вернемся к кейсу выше. Итак, вы спрашиваете у клиента:
– Уважаемый, а чем, зарабатываете на хлеб насущный?
А он вам отвечает:
– Ну, мы это…как его…подготовкой воздуха на предприятиях занимаемся. Осушка там, очистка от пыли, такие всякие вещи… Вы бы нам Газпром или Роснефть какую привели из контекста, мы бы вам тут же бюджет увеличили…
Тут у вас в голове вспыхивает лампочка, как сформулировать это в запрос, по которому и спроса побольше, и расширений можно натаскать:
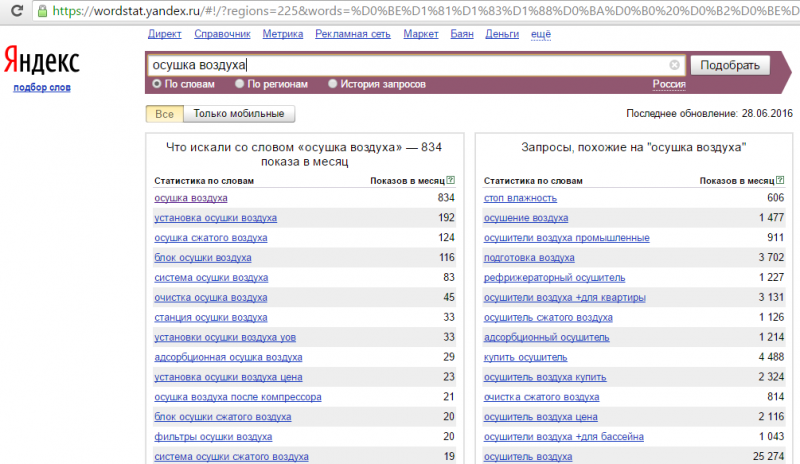
[осушка воздуха]
И верно, имеем 834 показа по всей России:
Но если вы специалист правильный, то должна загореться и вторая лампочка:
«Елки-зеленые, это ж придется всю осушку лопатить…»
Поясню на примере:
Если есть [осушка воздуха], то должна быть и [осушка газа], а если залезть поглубже, то выяснится, что бывает еще и [адсорбционная осушка], и до кучи – [абсорбционная осушка] и [осушка компрессора].
Отсюда вопрос: сам клиент вам этого не скажет (в 99% случаев), но если вы хотите обеспечить ему близкий к 100% охват – то должны найти это сами. На данный момент единственный способ сделать это – взять статистически достоверный массив по запросу [осушка] и проанализировать его при помощи обычного частотного словаря (Анализ групп в Key Collector или Megalemma, если массив менее 20 000).
Анализ групп в Key Collector, группировка «по отдельным словам»
Построенный частотный словарь в Megalemma
Подобная работа – жуткий костыль, она дорогая, неудобная, требует кучу времени, нужно вытащить из заказчика информацию, о том, что же он делает/не делает, сформулировать ее в ТЗ и транслировать обученному специалисту. Все это так, и я уже чувствую спиной недобрые взгляды адептов секты «все-можно-автоматизировать-просто-не-умеете».
Но в некоторых случаях подобная работа – действительно единственный выход, и я не вижу ни одного рабочего, реального метода в значительной мере ее ускорить. Примеров недостаточно?
Вот вам еще один. Имеем: компания занимается автосервисом, причем только дизель и только топливные системы дизельных двигателей.
Что им предложить в сем. ядре?
[ремонт форсунок] + расширения?
[ремонт тнвд] + расширения?
Вот что получилось в результате анализа частотного словаря по запросу [форсунка] – причем брали только запросы с общей частотностью от 30 по Wordstat (на момент анализа). Бизнес клиента, напомню, дизельный автосервис:
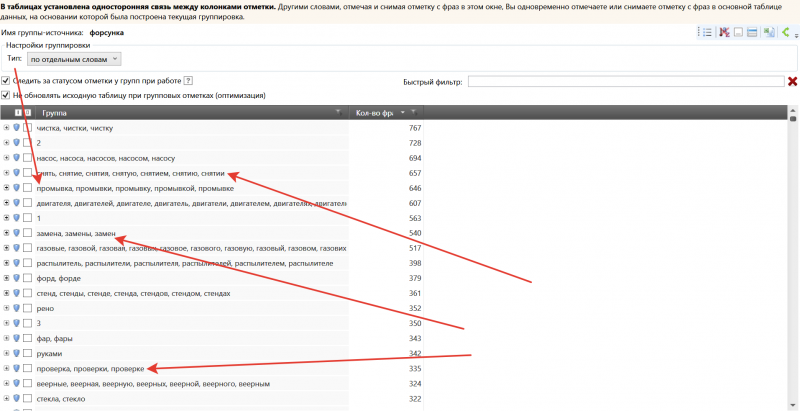
Анализируйте частотный словарь по верхнему (чаще однословному) запросу – выявите 100% реальных двусловных базисов
промывка форсунок
снятие форсунок
проверка форсунок
чистка форсунок
регулировка форсунок
шланг обратки форсунок
сломалась форсунка
замена форсунок
снимаем форсунки
разборка форсунки
стук форсунок
стоимость форсунок
ремонт форсунки
чистка форсунки
снять форсунки
проверка форсунки
проверить форсунки
промывать форсунки
заменить форсунки
присадка форсунки
настройка форсунки
отрегулировать форсунки
вытащить форсунки
вытаскивать форсунки
тестирование форсунки
подтекать форсунки
разобрать форсунки
регулировать форсунки
очистить форсунки
обслуживание форсунок
монтаж форсунок
то форсунок
техническое обслуживание форсунки
диагностирование форсунок
диагностика форсунок
сервис форсунки
Напомню, это только базисы, нужные для сбора расширений.
Пусть тот, кто скажет, что может выдумать все это из головы, без анализа частотника – первым бросит в меня камень. Также пусть присоединяются те, кто может это автоматизировать.
Здесь, к слову, можно немного схитрить. Например, по [форсунка] у вас условно 50000 запросов – Wordstat, подсказки, своя Метрика, базы – короче, сборная солянка. Частотник на 50000 анализировать долго. Возьмите для анализа только частотный словарь на основе Wordstat – его, как правило, всегда немного, 15-20% от общего массива. Просмотрите частотник, выпишите целевые двухсловники и затем по регулярке отфильтруйте нужные ключевые слова из общего массива. Точность упадет незначительно, а времени сэкономите порядком.
При этом, в моей практике были и более сложные примеры – когда СЯ нужно было составить для небанковской компании, работающей с выдачей ипотечных кредитов тем, кому отказали банки. То есть стояла задача уже на уровне запроса таргетировать пользователя по параметру «плохой заемщик для банка» и показывать рекламу именно ему. В этой ситуации единственным методом, способным обеспечить реальную, достоверную полноту стал анализ частотного словаря по запросам «ипотека/ипотечный».
В результате, даже в такой сверхперегретой нише были найдены запросы с одной стороны – целевые, с другой – неиспользуемые конкурентами:
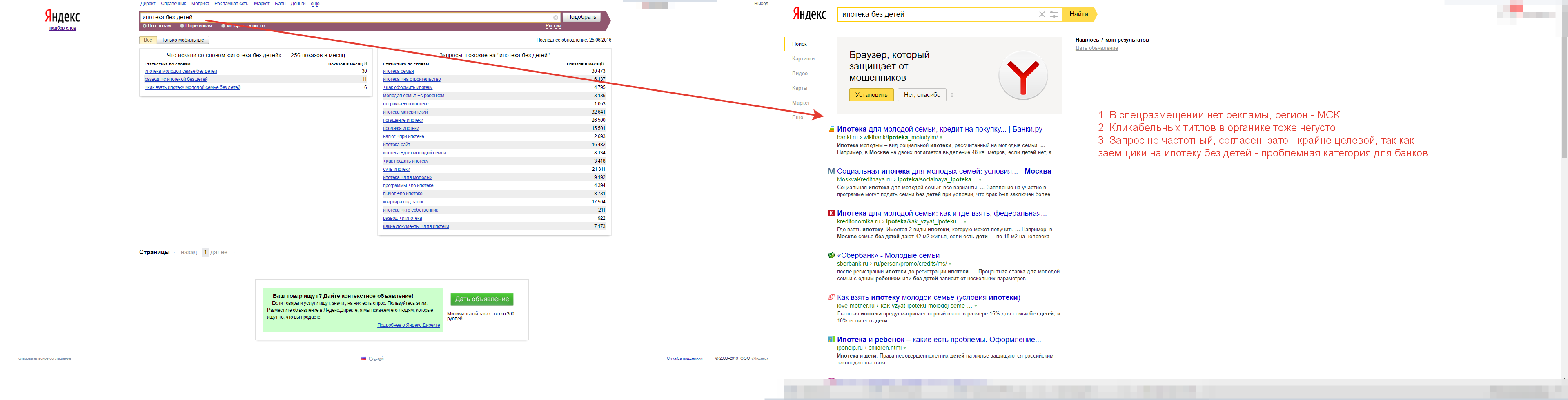
А вы знали, что заемщики без детей на ипотеку – «проблемная» категория для банков?
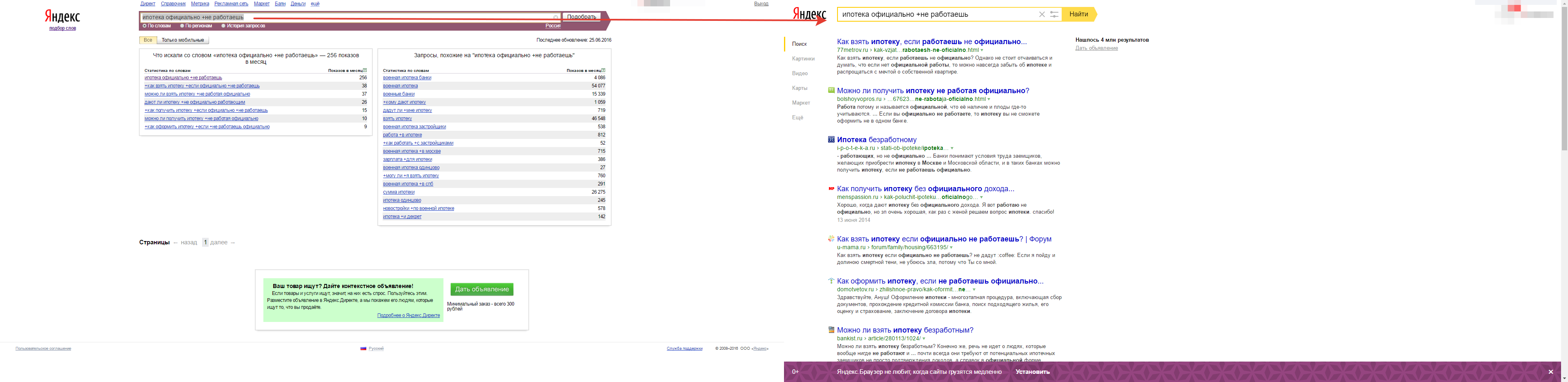
Зарплаты в конверте передают всем рантье горячий привет ;) Конкуренции аналогично нет
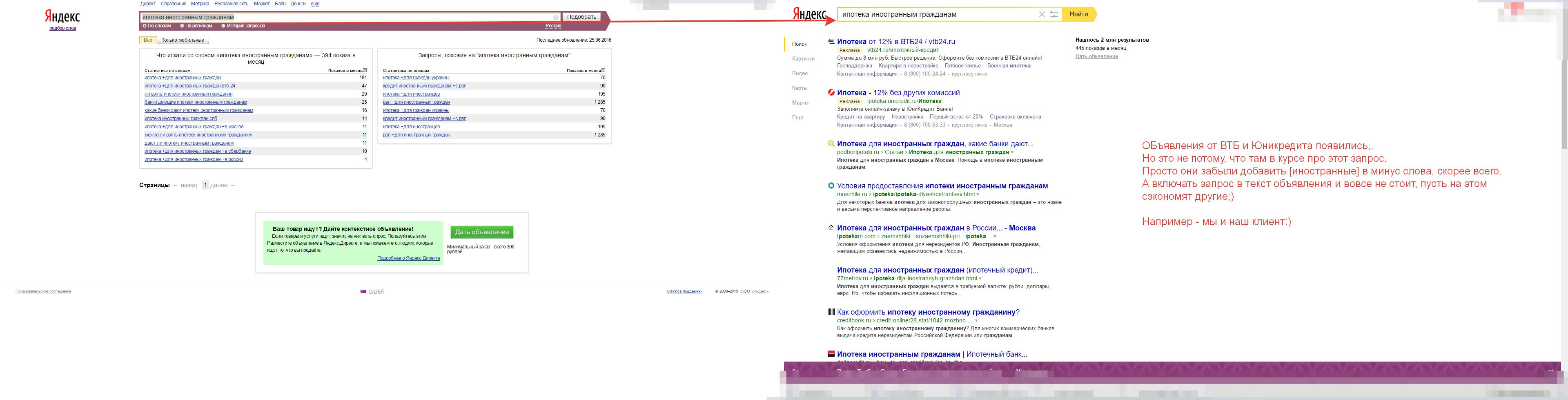
Горе-директолухи с безлимитным бюджетом. Миллионом больше, миллионом меньше… Искренняя ставка? Давай, до свидания!
Танцующая в темноте: как совместить бизнес и семантику при минусации?
Окей, ядро мы собрали. Частично автоматизированно, частично вручную – но кое-как собрали, согласовали с заказчиком и приступили к сборке самих рекламных кампаний. Вообще, в контексте этой и предыдущей главы «контекстные рекламные кампании» можно смело заменять на «SEO» и смысл не изменится – проблемы там глобально те же, решений – так же нет. Ровно так же, как и в контексте, в SEO нет автоматизированных решений для сбора базисов (и вряд ли появятся) и нет автоматизированных решений для очистки семантики от мусора (и никогда не будет).
Однако вернемся к нашим баранам – мы собрали ядро, и сейчас это так называемое «грязное» ядро. Нужно отделить зерна от плевел, то есть ненужные запросы от нужных, и заодно составить файл стоп-слов. Как работают стоп-слова, напоминать, надеюсь, не нужно.
Этот этап – самый проблемный, самый трудозатратный и не-автоматизируемый в принципе.
Поясню, о чем идет речь: у вас есть базис [проверка форсунок] и какая-то выборка по нему.
![Расширения Wordstat по запросу [проверка форсунок]](http://madcats.ru/wp-content/uploads/2016/06/2016-06-26_13-08-20-e1467315189786.png)
Расширения Wordstat по запросу [проверка форсунок]
Вам нужно отделить мусор:
![Мусорные расширения от базиса [проверка форсунок]](http://madcats.ru/wp-content/uploads/2016/06/musor-wordstat.png)
Мусорные расширения от базиса [проверка форсунок]
от нужного:
![Полезные расширения от базиса [проверка форсунок]](http://madcats.ru/wp-content/uploads/2016/06/nuznoe-wordstat.png)
Полезные расширения от базиса [проверка форсунок]
Выше я привел в качестве примера очевидные запросы. То есть очевидно, что «своими руками» для какого угодно бизнеса уйдет в стоп-слова.
А вот что делать дальше, как совместить 100% точность рекламы (показываем только тем, кто действительно нужен бизнесу) с максимальным охватом?
Как на этапе составления стоп-слов автоматизировать «нюансы» требований бизнеса к рекламе, на которые он имеет полное право?
Например, следственные действия с заказчиком выявили, что:
– бензиновые форсунки не проверяем.
– дизельные форсунки проверяем, но только не у отечественных авто.
– но у КамАЗ-ов проверяем!
То есть у нас имеются две проблемы:
- Нужно очень точно отделить нецелевые запросы от целевых, учитывая, что суммарный массив запросов огромен.
- Нужно сделать это в тесном контакте с бизнесом, но не «перегрузить» заказчика согласованиями СЯ – он ведь платит за то, чтобы вы работали над маркетингом, а не он.
Как мы в MOAB решаем эту проблему для наших клиентов?
Во-первых, стараемся хотя бы частично автоматизировать очистку, не потеряв в качестве. Делаем это на основе собственных скриптов и программ по типу «МегаЛеммы» – вот в этом видео краткий обзор, показана самая суть, а вот в этом – более подробно.
В основе процесса очистки – тот же самый частотный словарь, только обвешанный различной автоматизацией, которая позволяет оператору программы принимать максимально быстрое решение по каждому кластеру запросов – «оставляем/убираем/уточняем у заказчика».
То есть автоматизируется представление данных и обработка, но не принятие решение. В этом плане я продолжаю придерживаться мнения, что каждый бизнес – это как отпечатки пальцев: вот здесь вроде линии одинаковые, а тут – уже изгиб уникальный, ни на что не похожий. В разговоре с заказчиком это выглядит так: «форсунки продаем, ТНВД тоже, а дизель-сепараторы только с монтажом, а лампочки – от 10000 рублей, дворники не продаем, фильтра можно, но не очень маржинально, поставьте ставки пониже».
Поэтому всякие готовые списки стоп-слов, автоматизация на основе данных об отказах из Метрики – что для SEO, что для контекста – это все равно костыль, полезный очень избирательно.
Наверное, нужно что-то сказать и о взаимодействии с заказчиком в рамках процесса очистки. Мы разделяем этот этап на две части: сначала со слов заказчика пишем и согласовываем ТЗ для специалиста по работе с семантикой, в котором в общих чертах формулируем «что убирать/что оставлять».
Затем делаем общую скайп-конференцию, в которой участвует представитель заказчика, занятый на проекте наши специалист(ы) и руководитель. Непосредственно в процессе очистки семантики специалист сбрасывает в этот чат проблемные кластеры запросов, по которым выбор неочевиден. От заказчика требуется только оперативное «да-нет».
Резюмируя, могу сказать: если хотите работать с контекстной рекламой, совмещая с охват с чистотой трафика – готовьтесь к тому, что потребуется немало квалифицированных и мотивированных сотрудников, автоматизировать все – не получится по определению.
Авторучку верните: написание объявлений и создание кампаний
Строго говоря, следующий этап работы с запросами – группировка. Да, вы не ослышались – мы группируем запросы для контекста. Почему мы так делаем – тема для отдельной статьи, но если вкратце – если вы думаете, что имеете дело с запросом, то в реальности вы имеете дело с группой запросов, даже если не понимаете этого.
И да, кластеризация по топу – здесь как мертвому припарки. Как это выглядит на практике – снова сошлюсь на видео, ссылка на которое было выше, но будьте готовы потратить 40 минут и хорошенько все осмыслить.
В рамках данной статьи я воздержусь от обсуждения того, как автоматизировать группировку запросов – так как надо будет писать, зачем она вообще нужна. Тогда и без того длинная статья станет совсем затянутой – поэтому я сразу перейду к обсуждению вопроса о написании описаний и заголовков объявлений.
Общий смысл проблемы: можно ли автоматизировать создание кликабельных заголовков и описаний объявлений (+расширений, + доп.ссылок) в случае Директа?
Я бы ответил на этот вопрос так: можно, если массив рекламируемых объектов – однороден. То есть если вы рекламируете товарный фид на 100000 товаров, и все эти товары более-менее однородны – не составит труда сделать корректные с литературной точки зрения шаблоны для описаний и заголовков и подставить в них переменные с названием товара и артикулом.
Классический пример – автозапчасти.
Допустим, что мы имеем некий набор переменных, которые присутствуют в каждом товаре из нашего фида. Любая из систем автоматизации контекста (Elama, K-50, Seodroid, Direct Manager и другие), имеет в своем арсенале функционал для создания шаблонов заголовков и текстов. С их помощью мы можем соорудить подобные заготовки:
Купите %vendor% %artikul% по цене %price% руб – для заголовка
и
%description% с доставкой по РФ
В итоге при выгрузке в аккаунт эти шаблоны преобразуются в заголовки с названием бренда, артикулом товара и его ценой, и в тексты с описанием, при условии, конечно, что все эти переменные заполнены в фиде.
При этом нужно учесть, что переменные при подстановке значений могут отличаться количеством знаков. Чтобы избежать возможных неприятностей при загрузке, стоит предусмотреть несколько вариантов шаблонов, в которых использовать разное количество переменных.
Внимательно работайте с выбором переменной для ключевого слова в таких случаях. Наиболее очевидный вариант – поставить в качестве ключевого слова сам артикул товара/самый короткий вариант названия. Но в случае с артикулом вас может поджидать немало опасностей, о них – на Baltic Digital Days 12 августа.
Если же для загрузки однородных товарных фидов из автоматизации используется лишь Коммандер и Excel, подобную операцию не составит труда провести с помощью нескольких несложных макросов по такому же алгоритму.
В том случае, если вы работаете с неким неоднородным массивом, то лично я придерживаюсь точки зрения, что 100% автоматизация возможна только в ущерб кликабельности.
Поясню свою мысль: у вас есть массив запросов-расширений от базиса [промывка форсунок]. Практическая необходимость – добиться максимально возможной степени вхождения каждого пользовательского запроса в текст описания и заголовка, совместив это с литературной корректностью и требованиями модерации/Директа как по размеру текста, так и по его смыслу.
В этой ситуации невозможно придумать шаблон, который будет отвечать всем указанным требованиям.
Максимум возможного – придумать некий «общий» шаблон оформления всего объявления, задействующий все его элементы. В этот шаблон можно вставлять (например, в Excel) конкретные ключевые слова, и уже потом отдавать этот шаблон на редактирование копирайтеру, специализированному именно на такой работе.
Вместе с собственно файлом с объявлений я бы рекомендовал выдавать копирайтеру файл ТЗ, в котором расписано УТП бизнеса для данной конкретной категории товаров по убыванию приоритета. В таком случае копирайтер сможет корректировать объявления, сохраняя понимание, какой информацией в них можно пожертвовать в том случае, если исходный запрос очень длинный, а какую нужно сохранить, возможно, за счет переноса в доп. ссылки или расширения.
Но в любом случае данная работа, в массе своей остается ручной. Даже когда я ищу что-то для себя, я очень скептически отношусь к объявлениям, в которых явно угадывается «некорректированный» шаблон формата:
Если вы собираетесь открыть агентство по работе с контекстной рекламой, то будьте готовы к тому, что для этого этапа вам понадобятся 2-3 копирайтера и 1 редактор.
Казино начинает и выигрывает: управление ставками
Наверное, это единственный раздел в этом тексте, где писать особо нечего. Рынок управления ставками – это рынок Директа, и тут масса сервисов, начиная от e-lama.ru и заканчивая Direct Manager/SeoDroid/K50.
Управление ставками в Директе действительно экономит деньги, об этом хорошо рассказал Алексей Довжиков вот тут (презентация, слайд 85/видео), и я не вижу смысла повторяться. Могу со своей стороны подтвердить – заявленные Алексеем цифры реальны, в моей практике был кейс, когда биддер (в данном конкретном случае – Direct Manager), помог уменьшить цену лида на большом массиве кампаний на 35-40%, при условии что трафик и количество заявок осталось на том же уровне, что и до подключения.
Чего же не хватает на рынке?
- Больше сервисов, работающих с большими (более 10 000 товаров) фидами без багов и глюков. Пальцем показывать пока не буду, постараюсь показать на Baltic Digital Days (это же естественная ссылка, верно? Да еще и без реферера! А скидки на конфу – в рассылке MOAB в начале июля).
- Больше сервисов, умеющих отключать товарные объявления и управлять ставками на них, в зависимости от наличия товара.
- Больше скорости реакции для API Директа.
- Больше баллов для Директа (когда их уже начнут продавать?
Возможно, стоило бы написать больше о расчете искренней ставки и подходах к управлению ставками в целом, но это тоже придется оставить на потом – и так в статье уже 16 000 знаков без пробелов
В целом можно еще раз отметить, что управление ставками – практически единственный этап в производстве контекстной рекламы, автоматизация которого сравнительно проста, очевидна, объективно необходима и представлена на рынке в виде сервисов на любой вкус и кошелек.
Капитальные инвестиции: почему у вас контекст дорогой?
Формально этот раздел статьи не имеет отношения к автоматизации контекста. Но он имеет самое прямое отношение к автоматизации получения лидов из контекста, и я не могу не написать об этом.
Обычно, когда заказчик не состоянии платить за лиды столько, сколько того требует аукцион в его тематике, начинаются возгласы «Контекст не работает!». После этого нанимается новый специалист по контексту, история повторяется – и так до бесконечности.
Проблема в том, что самый дорогой, самый сложный, самый не-автоматизируемый раздел в работе с контекстом – это работа с сайтом. По опыту, если в вашем СЯ 10000 ключей, то «в среднем по больнице», это около 250-400 отдельных узких пользовательских проблем, имеющих свою специфику и требующих своего, отдельного контентного решения.
Кластеризация СЯ – как раз не проблема, а вот что делать с уже кластеризованным ядром? 95-97% бизнесов не имеют средств на то, чтобы работать с кластеризованными проблемами – то есть все сводится обычно к тому, что весь трафик сливается на лендинг с подменой заголовков на основе Yagla или аналогичного сервиса.
Создание контента, каталога товаров, ценовых предложений и пр., которые бы обеспечивали качественный ответ в каждом отдельном случае, на каждой кластеризованной странице – процесс настолько дорогой, настолько завязанный на специфические компетенции заказчика, что в условиях массового рынка на данный момент это нереально или же реально для компаний с оборотом как минимум от 100-200 млн рублей в год.
Обычно нечто подобное (sic! – «подобное», так как контент все равно унылый почти всегда) делают для SEO, но лиды из контекста как раз потому и дорогие, что дальше «лендинг+Yagla» в контексте люди не ходят.
Как это работает: не решили конкретную узкую проблему конкретного пользователя, попытались продать ему свой пафосный лендинг с «общей» информацией => завоевали доверие меньшей части аудитории => получили меньше контактов => таким образом, при одинаковых расходах на рекламу цена лида у вас и у того, кто «проблему» для пользователя решает – может отличаться в 2-3 раза как минимум.
И это не говоря о том, что качество решения пользовательской проблемы не только «напрямую» влияет на цену лида, но и «эхом» влияет на коэффициент качества в Директе, который также, в свою очередь, влияет на цену клика.
P.S.: ничего не имею против сервиса Yagla, иногда и сам его использую. Это как раз та ситуация, когда сервис – хороший, просто его используют неправильно, а свой собственный фейл списывают на «контекст не работает/лендинг плохой/лиды дорогие».
У меня все записано: аналитика и тестирование гипотез
Последний этап работы с контекстной рекламой, автоматизация которого важна и необходима – автоматизация учета лидов в разрезе источника их происхождения. Подобный анализ не требует больших усилий в случае заявок/онлайн покупок/сообщений в чат/заявок на обратный звонок, однако все немного сложнее, когда речь идет об анализе звонков.
Здесь существует выбор между статическим (дешево и сердито) и динамическим (дорого и долго) колл-трекингом.
С одной стороны, главный месседж сервисов колл-трекинга – «привязываем звонок к фразе». В то же время при работе с низкочастоткой фраза чаще всего неинформативна – серебряных пуль вообще не бывает, и поиск отдельных фраз, особенно – низкочастотных, которые генерируют звонки почему-то лучше, чем другие похожие фразы – занятие чаще всего бессмысленное. Плюс ко всему, это осложняется тем, что если речь идет о низкочастотке, то статистики по одной отдельной фразе – всегда мало.
То есть точность «до фразы» на самом деле большинству бизнесов для практической аналитики не нужна, достаточно точности «до объявления» или же «до кампании», если архитектура кампаний у вас в аккаунте выстроена правильно.
В то же время, если динамически откручивать 1 номер сравнительно недорого (ситуация когда вообще всем пользователям на сайте показывается только номер в «родном» городе, и динамически подменяется только он), то что делать, если номеров 20-30? Если в каждом миллионнике я показываю пользователям отдельный виртуальный локальный номер, так как мне интересен трафик со всей РФ (стандартная ситуация как для b2b, так и для b2c) – в этом случае стоимость внедрения и работы «динамики» часто уже не окупает профит от получаемых аналитических данных.
Кроме того, в случае работы с отдельными конкретными сервисами есть вопросы к точности работы, невозможности подключать «свои» номера и сип-аккаунты, но это тоже тема для отдельной статьи.
В общем случае можно сказать, что при бюджете на контекст в месяц менее 200-300 тыс. руб. я бы рекомендовал ограничиться грамотным учетом «простых» заявок (чат, заявки, колл-бэк, онлайн покупки) и дешевым статическим колл-трекингом. Точности получаемых данных будет более чем достаточно для 95% бизнесов – а стоимость и трудозатратность внедрения снизится существенно.
Послесловие
В заключение хочу сказать, что автоматизация безусловно – одна из важнейших составляющих любого производства, в том числе и производства «горячего» трафика из контекста/SEO. Однако в последнее время автоматизация превратилась в некий культ, т.е. автоматизировать стало правильно «потому что это автоматизация». Говорю это безотносительно какого-либо конкретного сервиса или программы, исключительно с целью предостеречь начинающих специалистов.
- Помните: ни одна публичная автоматизация не подойдет под ваши задачи на 100%. Всегда что-то придется допиливать руками.
- Работая с любой автоматизацией, отделяйте «мифологию» и пиар-составляющую от потребностей вашей конкретной задачи. Помните о том, что составляющие «мифологии/упаковки» и «функционала» в любом коммерчески успешном продукте примерно равны.
- Считайте конкретные профиты от автоматизации. Очень часто возникают ситуации, когда дешевле и быстрее «китайский» метод – чтобы вырыть котлован, нужно миллион китайцев и ноль экскаваторов.
Горячих лидов вам и хороших продаж.



